1 Introducing the .NET Framework with C#
The .NET Framework is such a comprehensive platform that it can be a little difficult to describe. I have heard it described as a Development Platform, an Execution Environment, and an Operating System among other things. In fact, in some ways each of these descriptions is accurate, if not sufficiently precise.
The software industry has become much more complex since the introduction of the Internet. Users have become both more sophisticated and less sophisticated at the same time. (I suspect not many individual users have undergone both metamorphoses but as a body of users this has certainly happened). Folks who had never touched a computer less than five years ago are now comfortably including the Internet in their daily lives. Meanwhile, the technophile or professional computer user has become much more advanced, as have their expectations from software.
It is this collective expectation from software that drives our industry. Each time a software developer creates a successful new idea, they raise user expectations for the next new feature. In a way this has been true for years. But now software developers face the added challenge of addressing the Internet and Internet-users in many applications that in the past were largely unconnected. It is this new challenge that the .NET Framework directly addresses.
Popular Posts
-
 Getting Started (Continue) Look at the form with the title bar Form1. This is how your program will look like. Everything you will place on ...
Getting Started (Continue) Look at the form with the title bar Form1. This is how your program will look like. Everything you will place on ... -
4.3 Using the FCL “Give a man a fish and you feed him for a day. Teach a man to fish and you feed him for a lifetime.” The IO strea...
-
 Data Form Wizard Visual Basic also allows us to work with DataBinding with it's built-in feature "Data Form Wizard". We will h...
Data Form Wizard Visual Basic also allows us to work with DataBinding with it's built-in feature "Data Form Wizard". We will h... -
Tutorials Chapter 1 : What is SQL Server? Chapter 2 : Compare SQL Server and MS Access Chapter 3 : What is MSDE ? Chapter 4 : SQL Server Edi...
-
 Simple Binding Generating DataSet To generate a DataSet, select Data->Generate DataSet from the main menu. From the dialog that opens, as...
Simple Binding Generating DataSet To generate a DataSet, select Data->Generate DataSet from the main menu. From the dialog that opens, as... -
 Console Applications Console Applications are command-line oriented applications that allow us to read characters from the console, write ch...
Console Applications Console Applications are command-line oriented applications that allow us to read characters from the console, write ch... -
Input/Output with files C++ provides the following classes to perform output and input of characters to/from files: * ofstream: Stream c...
-
 Abstract Classes An abstract class is the one that is not used to create objects. An abstract class is designed to act as a base class (to b...
Abstract Classes An abstract class is the one that is not used to create objects. An abstract class is designed to act as a base class (to b... -
OOP Basics Visual Basic was Object-Based, Visual Basic .NET is Object-Oriented, which means that it's a true Object-Oriented Programming...
-
 A "service" is an application that can start automatically when the computer starts. There are two start up modes: 1. Automatic - ...
A "service" is an application that can start automatically when the computer starts. There are two start up modes: 1. Automatic - ...
Saturday, March 14, 2009
1.1 Code in a Highly Distributed World
1.1 Code in a Highly Distributed World
Software that addresses the Internet must be able to communicate. However, the Internet is not just about communication. This assumption has led the software industry down the wrong path in the past. Communication is simply the base requirement for software in an Inter-networked world.
In addition to communication other features must be established. These include, security, binary composeability and modularity (which I will discuss shortly), scalability and performance, and flexibility. Even these just scratch the surface, but they are a good start.
Here are some features that users will expect in the near future. Users will begin to expect to run code served by a server that is not limited to the abilities (or physical display window) of a browser. Users will begin to expect websites and server-side code to begin to compose themselves of data and functionality from various venders, giving the end-user flexible one-stop shopping. Users will expect their data and information to be both secured and to roam from site to site so that they don’t have to type it in over and again. These are tall orders, and these are the types of requirements that are addressed by the .NET Framework.
It is not possible for the requirements of the future to be addressed by a new programming language, or a new library of tools and reusable code. It is also not practical to require everyone to buy a new operating system to use that addresses the Internet directly. This is why the .NET Framework is a development environment, execution environment and Operating System.
One challenge for software in a highly distributed environment (like the Internet) is the fact that many components are involved, with different needs in terms of technology. For example, client software such as a browser or custom client has different needs then a server object or data-base element. Developers creating large systems often have to learn a variety of programming environments and languages just to create a single product.

Figure 1‑1 Internet Distributed Software
Take a look at Figure 1‑1. This depicts a typical arrangement of computers and software in a distributed application. This includes client/server communication on several tiers as well as peer-to-peer communication. In the past the tools that you used to develop code at each tier would likely be different, including different programming languages and code libraries.
The .NET Framework can be used to develop software logic at every point from one end to the other. This way you get to use the language and programming tools that you are comfortable with for each stage of the development process. Additionally, the .NET framework uses standards so that it is not necessary that each piece of the puzzle be implemented using the framework. These are the goals of the .NET Framework.
I will describe what all this means in detail shortly.
Software that addresses the Internet must be able to communicate. However, the Internet is not just about communication. This assumption has led the software industry down the wrong path in the past. Communication is simply the base requirement for software in an Inter-networked world.
In addition to communication other features must be established. These include, security, binary composeability and modularity (which I will discuss shortly), scalability and performance, and flexibility. Even these just scratch the surface, but they are a good start.
Here are some features that users will expect in the near future. Users will begin to expect to run code served by a server that is not limited to the abilities (or physical display window) of a browser. Users will begin to expect websites and server-side code to begin to compose themselves of data and functionality from various venders, giving the end-user flexible one-stop shopping. Users will expect their data and information to be both secured and to roam from site to site so that they don’t have to type it in over and again. These are tall orders, and these are the types of requirements that are addressed by the .NET Framework.
It is not possible for the requirements of the future to be addressed by a new programming language, or a new library of tools and reusable code. It is also not practical to require everyone to buy a new operating system to use that addresses the Internet directly. This is why the .NET Framework is a development environment, execution environment and Operating System.
One challenge for software in a highly distributed environment (like the Internet) is the fact that many components are involved, with different needs in terms of technology. For example, client software such as a browser or custom client has different needs then a server object or data-base element. Developers creating large systems often have to learn a variety of programming environments and languages just to create a single product.

Figure 1‑1 Internet Distributed Software
Take a look at Figure 1‑1. This depicts a typical arrangement of computers and software in a distributed application. This includes client/server communication on several tiers as well as peer-to-peer communication. In the past the tools that you used to develop code at each tier would likely be different, including different programming languages and code libraries.
The .NET Framework can be used to develop software logic at every point from one end to the other. This way you get to use the language and programming tools that you are comfortable with for each stage of the development process. Additionally, the .NET framework uses standards so that it is not necessary that each piece of the puzzle be implemented using the framework. These are the goals of the .NET Framework.
I will describe what all this means in detail shortly.
1.2 C#: A First Taste of Managed Code
1.2 C#: A First Taste of Managed Code
Software that is written using the .NET Framework is called Managed Code. (Legacy or traditional software is sometimes referred to as Unmanaged Code). I will define managed code later in this tutorial. But for now you should think of managed code as code that runs with the aid of an execution engine to promote the goals of Internet software. These goals include security, robustness, and object-oriented design, amongst others. Managed code is not interpreted, and does run in the native machine language of the host processor, but I am getting ahead of myself.
First things first, I would like to show a couple of examples of managed code written using the C# (pronounced see-sharp) language.
class App{
public static void Main(){
System.Console.WriteLine("Hello World!");
}
}
Figure 1‑2 HelloConsole.cs
This short application is written using the C# language. The C# language is just one of the many languages that can be used to write managed code. This source code generates a program that displays the string “Hello World!” to the command line and then exits.
using System.Windows.Forms;
using System.Drawing;
class MyForm:Form{
public static void Main(){
Application.Run(new MyForm());
}
protected override void OnPaint(PaintEventArgs e){
e.Graphics.DrawString("Hello World!", new Font("Arial", 35),
Brushes.Blue, 10, 100);
}
}
Figure 1‑3 HelloGUI.cs
This slightly longer source sample is the GUI or windowed version of the Hello World! application. It takes advantage of a few more of the features of the .NET Framework to create a window in which to draw the message string.
Both Figure 1‑2 and Figure 1‑3 are examples of complete C# applications. One of the goals of the .NET Framework is to increase developer productivity and flexibility. One important way to do this is to make software easier to write.
As you can see, the syntax of C# is an object oriented C-based syntax much like C++ or Java. This allows developers to build on previous experience when targeting the .NET Framework with their software.
Before moving on I would like to point out some very simple details to jumpstart your exposure to C#. First, C# source code is typically maintained in files with a .cs extension. Note that both Figure 1‑2 and Figure 1‑3 are labeled with .cs names indicating that they are complete, compileable C# modules.
Second, if you are writing an executable your application must define an entry point function. (Modules containing nothing but reusable components do not require an entry point, but can not be executed as stand-alone applications). With C# the entry point, if there is one, is always a static method named Main().
The Main() function can accept an array of strings as command line arguments, and it can also return an integer value. The class in which the Main() method is defined can be of any name. It is common to name this class App, but as you can see from Figure 1‑3, it is also ok to use another class name such as MyForm. When reading C# source code, look to the Main() method as a starting point.
Exercise 1‑1 Compile Sample Code
1. The source code in Figure 1‑2 is a complete C# application.
2. Type in the code or copy it from the source code distributed with this tutorial. Save it into a file with the .cs extension.
3. Use either Visual Studio .NET or the command line compiler (named CSC.exe) to compile the application into an executable.
1. Hint: If you are using the command line compiler, the following line would compile a single module into an executable.
csc /target:exe HelloConsole.cs
2. Hint: If you are using the Visual Studio IDE then you should create an empty C# project, and add your .cs file to the project. Then build it to compile the exe.
4. Run the executable.
5. Try modifying the source code a little to change the text of the string, or perhaps to print several lines to the console window.
Exercise 1‑2 Compile GUI Sample Code
1. The source code in Figure 1‑3 is a complete GUI application written in C#. It will display a window with some text on the Window.
2. Like you did in Exercise 1‑1 type in or copy the source code and save it in a .cs file.
3. Compile the source code using the command line compiler or the Visual Studio IDE.
1. Hint: If you are using Visual Studio you will need to add references for System.Drawing.dll, System.Windows.Forms.dll, and System.dll.
4. Run the new executable.
Exercise 1‑3 EXTRA CREDIT: Modify the GUI Application
1. Starting with the project from Exercise 1‑2 you will make modifications to the GUI application.
2. Make modifications to the code to draw text more than once on the window in various locations. Perhaps change the color of the text or the strings printed.
3. Consider using a for or while loop to algorithmically adjust the location of drawing the text to the screen.
Software that is written using the .NET Framework is called Managed Code. (Legacy or traditional software is sometimes referred to as Unmanaged Code). I will define managed code later in this tutorial. But for now you should think of managed code as code that runs with the aid of an execution engine to promote the goals of Internet software. These goals include security, robustness, and object-oriented design, amongst others. Managed code is not interpreted, and does run in the native machine language of the host processor, but I am getting ahead of myself.
First things first, I would like to show a couple of examples of managed code written using the C# (pronounced see-sharp) language.
class App{
public static void Main(){
System.Console.WriteLine("Hello World!");
}
}
Figure 1‑2 HelloConsole.cs
This short application is written using the C# language. The C# language is just one of the many languages that can be used to write managed code. This source code generates a program that displays the string “Hello World!” to the command line and then exits.
using System.Windows.Forms;
using System.Drawing;
class MyForm:Form{
public static void Main(){
Application.Run(new MyForm());
}
protected override void OnPaint(PaintEventArgs e){
e.Graphics.DrawString("Hello World!", new Font("Arial", 35),
Brushes.Blue, 10, 100);
}
}
Figure 1‑3 HelloGUI.cs
This slightly longer source sample is the GUI or windowed version of the Hello World! application. It takes advantage of a few more of the features of the .NET Framework to create a window in which to draw the message string.
Both Figure 1‑2 and Figure 1‑3 are examples of complete C# applications. One of the goals of the .NET Framework is to increase developer productivity and flexibility. One important way to do this is to make software easier to write.
As you can see, the syntax of C# is an object oriented C-based syntax much like C++ or Java. This allows developers to build on previous experience when targeting the .NET Framework with their software.
Before moving on I would like to point out some very simple details to jumpstart your exposure to C#. First, C# source code is typically maintained in files with a .cs extension. Note that both Figure 1‑2 and Figure 1‑3 are labeled with .cs names indicating that they are complete, compileable C# modules.
Second, if you are writing an executable your application must define an entry point function. (Modules containing nothing but reusable components do not require an entry point, but can not be executed as stand-alone applications). With C# the entry point, if there is one, is always a static method named Main().
The Main() function can accept an array of strings as command line arguments, and it can also return an integer value. The class in which the Main() method is defined can be of any name. It is common to name this class App, but as you can see from Figure 1‑3, it is also ok to use another class name such as MyForm. When reading C# source code, look to the Main() method as a starting point.
Exercise 1‑1 Compile Sample Code
1. The source code in Figure 1‑2 is a complete C# application.
2. Type in the code or copy it from the source code distributed with this tutorial. Save it into a file with the .cs extension.
3. Use either Visual Studio .NET or the command line compiler (named CSC.exe) to compile the application into an executable.
1. Hint: If you are using the command line compiler, the following line would compile a single module into an executable.
csc /target:exe HelloConsole.cs
2. Hint: If you are using the Visual Studio IDE then you should create an empty C# project, and add your .cs file to the project. Then build it to compile the exe.
4. Run the executable.
5. Try modifying the source code a little to change the text of the string, or perhaps to print several lines to the console window.
Exercise 1‑2 Compile GUI Sample Code
1. The source code in Figure 1‑3 is a complete GUI application written in C#. It will display a window with some text on the Window.
2. Like you did in Exercise 1‑1 type in or copy the source code and save it in a .cs file.
3. Compile the source code using the command line compiler or the Visual Studio IDE.
1. Hint: If you are using Visual Studio you will need to add references for System.Drawing.dll, System.Windows.Forms.dll, and System.dll.
4. Run the new executable.
Exercise 1‑3 EXTRA CREDIT: Modify the GUI Application
1. Starting with the project from Exercise 1‑2 you will make modifications to the GUI application.
2. Make modifications to the code to draw text more than once on the window in various locations. Perhaps change the color of the text or the strings printed.
3. Consider using a for or while loop to algorithmically adjust the location of drawing the text to the screen.
2 Managed Code and the CLR
2 Managed Code and the CLR
Remember that managed code is code written for (and with) the .NET Framework. Managed code is called managed because it runs under the constant supervision of an execution engine called the Common Language Runtime or CLR.

Figure 2‑1 Managed Code and the CLR
The CLR is similar to other existing execution engines such as the Java VM or Visual Basic. The CLR supplies memory management, type safety, code verifiability, thread management and security. However, the CLR also bears some important distinctions from previously existing environments.
First and foremost, managed code is never interpreted. This statement is so important that it is worth repeating. Unlike with other execution engines, code that runs under the supervision of the CLR runs natively in the machine language of the host CPU. I will touch on this in more detail shortly.
Secondly, the security model enforced by the CLR on managed code is different than the security of previous environments. Managed code does not run in a virtual machine, and it does not run in a sand-box. However, the Common Language Runtime does apply restrictions to managed code based on where the code comes from. Managed security is flexible and powerful feature. An entire tutorial in this series is devoted to this topic.
Before beginning to describe what and how the CLR does what it does, I would like to take a moment to address the need for managed code. Managed code makes it possible for applications to be composed of parts that they were never tested with, and that may not even have existed at the time of development.
For example, Acme Widgets sells their product with a website online. WeShipit Delivery Service provides shipping. If Acme publishes a shipping interface to their website, then WeShipit could become a shipping agent for Acme’s site. It is feasible, with managed code, for WeShipit’s shipping code and web interface code to plug right into the website for Acme without anybody at Acme lifting a finger, or even being aware of the addition to their site.
This kind of flexibility will create some exciting opportunities for the composition of software across the Internet. (Imagine an online game where the players can write software to define their characters and their characters’ items). However, it raises concerns of practical details like faulty or malicious components, performance, type compatibility and type safety. These are the reasons that a managed environment is necessary. However, the last thing software developers want is to suffer the performance-hit of an interpreted environment.
Remember that managed code is code written for (and with) the .NET Framework. Managed code is called managed because it runs under the constant supervision of an execution engine called the Common Language Runtime or CLR.

Figure 2‑1 Managed Code and the CLR
The CLR is similar to other existing execution engines such as the Java VM or Visual Basic. The CLR supplies memory management, type safety, code verifiability, thread management and security. However, the CLR also bears some important distinctions from previously existing environments.
First and foremost, managed code is never interpreted. This statement is so important that it is worth repeating. Unlike with other execution engines, code that runs under the supervision of the CLR runs natively in the machine language of the host CPU. I will touch on this in more detail shortly.
Secondly, the security model enforced by the CLR on managed code is different than the security of previous environments. Managed code does not run in a virtual machine, and it does not run in a sand-box. However, the Common Language Runtime does apply restrictions to managed code based on where the code comes from. Managed security is flexible and powerful feature. An entire tutorial in this series is devoted to this topic.
Before beginning to describe what and how the CLR does what it does, I would like to take a moment to address the need for managed code. Managed code makes it possible for applications to be composed of parts that they were never tested with, and that may not even have existed at the time of development.
For example, Acme Widgets sells their product with a website online. WeShipit Delivery Service provides shipping. If Acme publishes a shipping interface to their website, then WeShipit could become a shipping agent for Acme’s site. It is feasible, with managed code, for WeShipit’s shipping code and web interface code to plug right into the website for Acme without anybody at Acme lifting a finger, or even being aware of the addition to their site.
This kind of flexibility will create some exciting opportunities for the composition of software across the Internet. (Imagine an online game where the players can write software to define their characters and their characters’ items). However, it raises concerns of practical details like faulty or malicious components, performance, type compatibility and type safety. These are the reasons that a managed environment is necessary. However, the last thing software developers want is to suffer the performance-hit of an interpreted environment.
2.1 Intermediate Language, Metadata and JIT Compilation
2.1 Intermediate Language, Metadata and JIT Compilation
Managed code is not interpreted by the CLR. I mentioned that earlier. But how is it possible for native machine code to be verifiably type-safe, secure, and fault tolerant? The answer comes in threes: Common Intermediate Language, Metadata and JIT Compilation.
Common Intermediate Language (often called Intermediate Language or IL) is an abstracted assembly language. The designers of the .NET Framework worked with many professional and academic institutions (over the course of over five years) to define an assembly language for a CPU that doesn’t exist. One of the goals of IL, however, was to be completely CPU agnostic, to the extent that it will translate well for ANY CPU.
IL is high-level for an assembly language, and includes instructions for such advanced programming concepts as newing up an instance of an object or calling a virtual function. And when I said, “translate” in the previous paragraph, that’s exactly what I meant. The CLR translates these and every other IL instruction into a native machine language instruction at runtime, and then executes the code natively. This translation is called Just-In-Time Compilation or JIT Compiling.
So what about the third item? What about Metadata? The easiest way to understand metadata is to start with IL instructions. IL instructions describe the executable logic of your source code. They describe the many branches, loops, comparisons, etc. of software. The IL instructions embody the logic of your managed software. Metadata is all of the other stuff.
Metadata describes class definitions, method calls, parameter types and return values. Metadata describes binding rules for types found in external binary modules (called managed assemblies). Metadata literally describes every aspect of a program other than the literal executable logic.
In fact, a managed executable is nothing but IL and metadata. This is an important point. Traditional executables typically include the instructions of the program, but the definitions for things like classes and function calls are lost at compilation time. However, with managed executable files, the metadata and IL instructions always live together in the same file. A managed executable is IL and metadata.

Figure 2‑2 From Source Code to Managed Executable
This helps to complete the picture of managed code and JIT compilation. The JIT compiler, which is part of the CLR, uses both the metadata and the IL from a managed executable to create machine language instructions at runtime. Then, these machine language instructions are executed natively. However, in the process of JIT compiling the code some very important things happen. First, type-safety and security are verified. Second, code correctness is verified (no dangling memory references, or referencing unassigned data). Third, code executes at native speed. And fourth, processor independence comes along for the ride.

Figure 2‑3 From IL to Execution
Managed code and JIT compilation bring a lot to the equation. If a managed executable was ill-designed to break a security rule, the CLR will catch this at verification or JIT compilation time, and will refuse to execute the code. If a managed executable references unassigned data, or attempts to coerce a data-type into an incompatible type (through typecasting), the CLR will catch this and refuse to execute the code. And your code runs full speed on your hardware.
The CLR, through code management, will increase the functionality and robustness of your traditional console or GUI applications. However, for widely distributed applications that make use of components from many sources, the advantages of managed code are a necessity.
Managed code is not interpreted by the CLR. I mentioned that earlier. But how is it possible for native machine code to be verifiably type-safe, secure, and fault tolerant? The answer comes in threes: Common Intermediate Language, Metadata and JIT Compilation.
Common Intermediate Language (often called Intermediate Language or IL) is an abstracted assembly language. The designers of the .NET Framework worked with many professional and academic institutions (over the course of over five years) to define an assembly language for a CPU that doesn’t exist. One of the goals of IL, however, was to be completely CPU agnostic, to the extent that it will translate well for ANY CPU.
IL is high-level for an assembly language, and includes instructions for such advanced programming concepts as newing up an instance of an object or calling a virtual function. And when I said, “translate” in the previous paragraph, that’s exactly what I meant. The CLR translates these and every other IL instruction into a native machine language instruction at runtime, and then executes the code natively. This translation is called Just-In-Time Compilation or JIT Compiling.
So what about the third item? What about Metadata? The easiest way to understand metadata is to start with IL instructions. IL instructions describe the executable logic of your source code. They describe the many branches, loops, comparisons, etc. of software. The IL instructions embody the logic of your managed software. Metadata is all of the other stuff.
Metadata describes class definitions, method calls, parameter types and return values. Metadata describes binding rules for types found in external binary modules (called managed assemblies). Metadata literally describes every aspect of a program other than the literal executable logic.
In fact, a managed executable is nothing but IL and metadata. This is an important point. Traditional executables typically include the instructions of the program, but the definitions for things like classes and function calls are lost at compilation time. However, with managed executable files, the metadata and IL instructions always live together in the same file. A managed executable is IL and metadata.

Figure 2‑2 From Source Code to Managed Executable
This helps to complete the picture of managed code and JIT compilation. The JIT compiler, which is part of the CLR, uses both the metadata and the IL from a managed executable to create machine language instructions at runtime. Then, these machine language instructions are executed natively. However, in the process of JIT compiling the code some very important things happen. First, type-safety and security are verified. Second, code correctness is verified (no dangling memory references, or referencing unassigned data). Third, code executes at native speed. And fourth, processor independence comes along for the ride.

Figure 2‑3 From IL to Execution
Managed code and JIT compilation bring a lot to the equation. If a managed executable was ill-designed to break a security rule, the CLR will catch this at verification or JIT compilation time, and will refuse to execute the code. If a managed executable references unassigned data, or attempts to coerce a data-type into an incompatible type (through typecasting), the CLR will catch this and refuse to execute the code. And your code runs full speed on your hardware.
The CLR, through code management, will increase the functionality and robustness of your traditional console or GUI applications. However, for widely distributed applications that make use of components from many sources, the advantages of managed code are a necessity.
2.2 Automatic Memory Management
2.2 Automatic Memory Management
The Common Language Runtime does more for your C# and .NET managed executable than just JIT compile them. The CLR offers automatic thread management, security management, and perhaps most importantly, memory management.
Memory management is an unavoidable part of software development. Commonly memory management, to one degree or another, is implemented by the application. It is its sheer commonality combined with its potential complexity, however, that make memory management better suited as a system service.
Here are some simple things that can go wrong in software.
· Your code can reference a data block that has not been initialized. This can cause instability and cause erratic behavior in your software.
· Software may fail to free up a memory block after it is finished with the data. Memory leaks can cause an application or an entire system to fail.
· Software may reference a memory block after it has been freed up.
There may be other memory-management related bugs, but the great majority will fall under one of these main categories.
Developers are increasingly taxed with complex requirements, and the mundane task of managing the memory for objects and data types can be tedious. Furthermore, when executing component code from an un-trusted source (perhaps across the internet) in your same process with your main application code you want to be absolutely certain that the un-trusted code cannot obtain access to the memory for your data. These things create the necessity for automatic memory management for managed code.
All programs running under the .NET Framework or Common Language Runtime allocate memory from a managed heap. The managed heap is maintained by the CLR. It is used for all memory resources, including the space required to create instances of objects, as well as the memory required for data buffers, strings, collections, stacks and caches.
The managed heap knows when a block of data is referenced by your application (or by another object in the heap), in which case that object will be left alone. But as soon as a block of memory becomes an unreferenced item, it is subject to garbage collection. Garbage collection is an automatic part of the processing of the managed heap, and happens as needed.
Your code will never explicitly clean-up, delete, or free a block of memory, so therefore it is impossible to leak memory. Memory is considered garbage when it is no longer referenced by your code, so therefore it is impossible for your code to reference a block of memory that has already been freed or garbage collected. Finally, because the managed heap is a pointer-less environment (at least from your managed code’s point of view), it is possible for the code verifier to make it impossible for managed code to read a block of memory that has not been written to first.
The managed heap makes all three of the major memory management bugs an impossibility.
The Common Language Runtime does more for your C# and .NET managed executable than just JIT compile them. The CLR offers automatic thread management, security management, and perhaps most importantly, memory management.
Memory management is an unavoidable part of software development. Commonly memory management, to one degree or another, is implemented by the application. It is its sheer commonality combined with its potential complexity, however, that make memory management better suited as a system service.
Here are some simple things that can go wrong in software.
· Your code can reference a data block that has not been initialized. This can cause instability and cause erratic behavior in your software.
· Software may fail to free up a memory block after it is finished with the data. Memory leaks can cause an application or an entire system to fail.
· Software may reference a memory block after it has been freed up.
There may be other memory-management related bugs, but the great majority will fall under one of these main categories.
Developers are increasingly taxed with complex requirements, and the mundane task of managing the memory for objects and data types can be tedious. Furthermore, when executing component code from an un-trusted source (perhaps across the internet) in your same process with your main application code you want to be absolutely certain that the un-trusted code cannot obtain access to the memory for your data. These things create the necessity for automatic memory management for managed code.
All programs running under the .NET Framework or Common Language Runtime allocate memory from a managed heap. The managed heap is maintained by the CLR. It is used for all memory resources, including the space required to create instances of objects, as well as the memory required for data buffers, strings, collections, stacks and caches.
The managed heap knows when a block of data is referenced by your application (or by another object in the heap), in which case that object will be left alone. But as soon as a block of memory becomes an unreferenced item, it is subject to garbage collection. Garbage collection is an automatic part of the processing of the managed heap, and happens as needed.
Your code will never explicitly clean-up, delete, or free a block of memory, so therefore it is impossible to leak memory. Memory is considered garbage when it is no longer referenced by your code, so therefore it is impossible for your code to reference a block of memory that has already been freed or garbage collected. Finally, because the managed heap is a pointer-less environment (at least from your managed code’s point of view), it is possible for the code verifier to make it impossible for managed code to read a block of memory that has not been written to first.
The managed heap makes all three of the major memory management bugs an impossibility.
2.3 Language Concepts and the CLR
2.3 Language Concepts and the CLR
Managed code runs with the constant maintenance of the Common Language Runtime. The CLR provides memory management, type management, security and threading. In this respect, the CLR is a runtime environment. However, unlike typical runtime environments, managed code is not tied to any particular programming language.
You have most likely heard of C# (pronounced See-Sharp). C# is a new programming language built specifically to write managed software targeting the .NET Framework. However, C# is by no means the only language that you can use to write managed code. In fact, any compiler developer can choose to make their compiler generate managed code. The only requirement is that their compiler emits an executable comprised of valid IL and metadata.
At this time Microsoft is shipping five language compilers/assemblers with the .NET Framework. These are C#, Visual Basic, C++, Java Script, and IL. (Yes, you can write managed code directly in IL, however this will be as uncommon as it is to write assembly language programs today). In addition to the five languages shipping with the framework, Microsoft will release a Java compiler that generates managed applications that run on the CLR.
In addition to Microsoft’s language compilers, third parties are producing language compilers for over 20 computer languages, all targeting the .NET Framework. You will be able write managed applications in your favorite languages including Eiffel, PERL, COBOL and Java amongst others.
Language agnosticism is really cool. Your PERL scripts will now be able to take advantage of the same object libraries that you use in your C# applications. Meanwhile, your friends and coworkers will be able to use your reusable components whether or not they are using the same programming language as you. This division of runtime engine, API (Application Programmer Interface), and language syntax is a real win for developers.
The CLR does not need to know (nor will it ever know) anything about any computer language other than IL. All managed software is compiled down to IL instructions and metadata. These are the only things that the CLR deals with. The reason this is important is because it makes any computer language an equal citizen from the point of view of the CLR. By the time JIT compilation occurs your program is nothing but logic and metadata.
IL itself is geared towards object oriented languages. However, compilers for procedural or scripted languages can easily produce IL to represent their logic.
Managed code runs with the constant maintenance of the Common Language Runtime. The CLR provides memory management, type management, security and threading. In this respect, the CLR is a runtime environment. However, unlike typical runtime environments, managed code is not tied to any particular programming language.
You have most likely heard of C# (pronounced See-Sharp). C# is a new programming language built specifically to write managed software targeting the .NET Framework. However, C# is by no means the only language that you can use to write managed code. In fact, any compiler developer can choose to make their compiler generate managed code. The only requirement is that their compiler emits an executable comprised of valid IL and metadata.
At this time Microsoft is shipping five language compilers/assemblers with the .NET Framework. These are C#, Visual Basic, C++, Java Script, and IL. (Yes, you can write managed code directly in IL, however this will be as uncommon as it is to write assembly language programs today). In addition to the five languages shipping with the framework, Microsoft will release a Java compiler that generates managed applications that run on the CLR.
In addition to Microsoft’s language compilers, third parties are producing language compilers for over 20 computer languages, all targeting the .NET Framework. You will be able write managed applications in your favorite languages including Eiffel, PERL, COBOL and Java amongst others.
Language agnosticism is really cool. Your PERL scripts will now be able to take advantage of the same object libraries that you use in your C# applications. Meanwhile, your friends and coworkers will be able to use your reusable components whether or not they are using the same programming language as you. This division of runtime engine, API (Application Programmer Interface), and language syntax is a real win for developers.
The CLR does not need to know (nor will it ever know) anything about any computer language other than IL. All managed software is compiled down to IL instructions and metadata. These are the only things that the CLR deals with. The reason this is important is because it makes any computer language an equal citizen from the point of view of the CLR. By the time JIT compilation occurs your program is nothing but logic and metadata.
IL itself is geared towards object oriented languages. However, compilers for procedural or scripted languages can easily produce IL to represent their logic.
2.4 Advanced Topics for the Interested
2.4 Advanced Topics for the Interested
If you are one of those that just must know some of the details, then this section is for you. But, if you are looking for a practical but brief overview of the .NET Framework, you can skip to section Error! Reference source not found., Error! Reference source not found., right now and come back to this section when you have more time.
In specific, I am going to explain in more detail JIT compilation and garbage collection.
The first time that a managed executable references a class or type (such as a structure, interface, enumerated type or primitive type) the system must load the code module or managed module that implements the type. At the point of loading, the JIT compiler creates method stubs in native machine language for every member method in the newly loaded class. These stubs include nothing but a jump into a special function in the JIT compiler.
Once the stub functions are created, the system fixes up any method calls in the referencing code to point to the new stub functions. At this time no JIT compilation of the type’s code has occurred. However, if a managed application references a managed type, it is likely to call methods on this type (in fact it is almost inevitable).
When one of the stub functions is called, the JIT compiler looks up the source code (IL and metadata) in the associated managed module, and builds native machine code for the function on the fly. Then, it replaces the stub function with a jump to the newly JIT compiled function. The next time this same method is called in source code, it will be executed full speed without any need for compilation or any extra steps.
The good thing about this approach is that the system never wastes time JIT compiling methods that won’t be called by this run of your application.
Finally, when a method is JIT compiled, any types that it references are checked by the CLR to see if they are new to this run of the application. If this is indeed the first time a type has been referenced, then the whole process starts over again for this type. This is how JIT compilation progresses throughout the execution of a managed application.
Take a deep breath, and exhale slowly, because now I am going to switch gears and discuss the garbage collector.
Garbage collection is a process that takes time. The CLR must halt all or most of the threads in your managed application when garbage buffers and garbage objects are cleaned out of the managed heap. Performance is important, so it can help to understand the garbage collection process.
Garbage collection is not an active process. Garbage collection is passive and will only happen when there is not enough free memory to fulfill an instruction to new-up an instance of an object or memory buffer. If there is not enough free memory then a garbage collection occurs in the attempt to find enough free memory.
When garbage collection occurs, the system finds all objects referenced by local (stack) variables and global variables. These objects are not garbage, because they are referenced by your running threads. After this, the system searches referenced objects for more object references. These objects are also not garbage because they are referenced. This continues until the last referenced object is found. All other objects are garbage and are released.

Figure 2‑4 Managed Objects in the Managed Heap
During garbage collection, the memory consumed by garbage objects is compacted and referenced objects are moved to fill in the newly freed memory space. As a result, memory is used much more efficiently in managed applications, because memory fragmentation is impossible.
Although the garbage collection itself can be a time consuming process (while still usually less than a split second), memory allocation is a very speedy process. The reason for this is that memory is always allocated contiguously on the managed heap (similar to a stack allocation). So the great majority of memory allocations amount to nothing other than a pointer addition.
Of course there are many more details to JIT compilation and the managed heap, however these advanced facts might whet your appetite to look further into these topics in the future. (See Jeffrey Richter’s MSDN Article for more information on the garbage collector).
If you are one of those that just must know some of the details, then this section is for you. But, if you are looking for a practical but brief overview of the .NET Framework, you can skip to section Error! Reference source not found., Error! Reference source not found., right now and come back to this section when you have more time.
In specific, I am going to explain in more detail JIT compilation and garbage collection.
The first time that a managed executable references a class or type (such as a structure, interface, enumerated type or primitive type) the system must load the code module or managed module that implements the type. At the point of loading, the JIT compiler creates method stubs in native machine language for every member method in the newly loaded class. These stubs include nothing but a jump into a special function in the JIT compiler.
Once the stub functions are created, the system fixes up any method calls in the referencing code to point to the new stub functions. At this time no JIT compilation of the type’s code has occurred. However, if a managed application references a managed type, it is likely to call methods on this type (in fact it is almost inevitable).
When one of the stub functions is called, the JIT compiler looks up the source code (IL and metadata) in the associated managed module, and builds native machine code for the function on the fly. Then, it replaces the stub function with a jump to the newly JIT compiled function. The next time this same method is called in source code, it will be executed full speed without any need for compilation or any extra steps.
The good thing about this approach is that the system never wastes time JIT compiling methods that won’t be called by this run of your application.
Finally, when a method is JIT compiled, any types that it references are checked by the CLR to see if they are new to this run of the application. If this is indeed the first time a type has been referenced, then the whole process starts over again for this type. This is how JIT compilation progresses throughout the execution of a managed application.
Take a deep breath, and exhale slowly, because now I am going to switch gears and discuss the garbage collector.
Garbage collection is a process that takes time. The CLR must halt all or most of the threads in your managed application when garbage buffers and garbage objects are cleaned out of the managed heap. Performance is important, so it can help to understand the garbage collection process.
Garbage collection is not an active process. Garbage collection is passive and will only happen when there is not enough free memory to fulfill an instruction to new-up an instance of an object or memory buffer. If there is not enough free memory then a garbage collection occurs in the attempt to find enough free memory.
When garbage collection occurs, the system finds all objects referenced by local (stack) variables and global variables. These objects are not garbage, because they are referenced by your running threads. After this, the system searches referenced objects for more object references. These objects are also not garbage because they are referenced. This continues until the last referenced object is found. All other objects are garbage and are released.

Figure 2‑4 Managed Objects in the Managed Heap
During garbage collection, the memory consumed by garbage objects is compacted and referenced objects are moved to fill in the newly freed memory space. As a result, memory is used much more efficiently in managed applications, because memory fragmentation is impossible.
Although the garbage collection itself can be a time consuming process (while still usually less than a split second), memory allocation is a very speedy process. The reason for this is that memory is always allocated contiguously on the managed heap (similar to a stack allocation). So the great majority of memory allocations amount to nothing other than a pointer addition.
Of course there are many more details to JIT compilation and the managed heap, however these advanced facts might whet your appetite to look further into these topics in the future. (See Jeffrey Richter’s MSDN Article for more information on the garbage collector).
3 Visual Studio .NET
3 Visual Studio .NET
This section is a short one, but I cannot go on without mentioning Visual Studio .NET. Visual Studio .NET is not part of the .NET Framework. However, it deserves mention in an introduction of the .NET Framework. Visual Studio is an integrated development environment published by Microsoft for writing Windows programs. Visual Studio .NET can also be used to write managed applications in C#, C++, Visual Basic and any other language (such as Perl) that is integrated into the environment by a third-party.
Visual Studio .NET itself is a partially managed application and requires the .NET Framework to run. Visual Studio .NET is a very user-friendly and productive environment in which to write managed applications. It includes many helpful wizards for creating code, as well as useful features such as context coloring, integrated online help, auto completion and edit-time error notification. But, you do not need Visual Studio .NET to execute or develop managed software.
I am not suggesting that you avoid Visual Studio .NET. It is a great product. In fact a large portion of a later tutorial in this series is devoted to teaching you to get the most out of Visual Studio as a C# programmer. But, it is important that you recognize Visual Studio .NET and the .NET Framework as different products.
The Framework is the infrastructure for managed code. The .NET Framework includes the CLR as well as other components that I will be discussing shortly. The .NET Framework also ships with an SDK (Software Developers Kit) that includes command line compilers for C#, C++, Visual Basic, and IL.
The bottom line is that the Framework is all you need to develop C# applications. That being said Visual Studio .NET can increase your enjoyment and productivity significantly.
This section is a short one, but I cannot go on without mentioning Visual Studio .NET. Visual Studio .NET is not part of the .NET Framework. However, it deserves mention in an introduction of the .NET Framework. Visual Studio is an integrated development environment published by Microsoft for writing Windows programs. Visual Studio .NET can also be used to write managed applications in C#, C++, Visual Basic and any other language (such as Perl) that is integrated into the environment by a third-party.
Visual Studio .NET itself is a partially managed application and requires the .NET Framework to run. Visual Studio .NET is a very user-friendly and productive environment in which to write managed applications. It includes many helpful wizards for creating code, as well as useful features such as context coloring, integrated online help, auto completion and edit-time error notification. But, you do not need Visual Studio .NET to execute or develop managed software.
I am not suggesting that you avoid Visual Studio .NET. It is a great product. In fact a large portion of a later tutorial in this series is devoted to teaching you to get the most out of Visual Studio as a C# programmer. But, it is important that you recognize Visual Studio .NET and the .NET Framework as different products.
The Framework is the infrastructure for managed code. The .NET Framework includes the CLR as well as other components that I will be discussing shortly. The .NET Framework also ships with an SDK (Software Developers Kit) that includes command line compilers for C#, C++, Visual Basic, and IL.
The bottom line is that the Framework is all you need to develop C# applications. That being said Visual Studio .NET can increase your enjoyment and productivity significantly.
4 Reusable Components and the FCL
4 Reusable Components and the FCL
Up to this point I have spoken quite a bit about the goals of the .NET Framework, as well as what it means to write managed code and what the CLR does for your software. The Common Language Runtime is the foundation for everything managed, and as such is a very important piece of the .NET puzzle. But in your day to day programming you will spend much more energy discovering, utilizing, and extending the reusable components found in the Framework Class Library.
The Framework Class Library or FCL nothing short of a massive collection of classes, structures, enumerated types and interfaces defined and implemented for reuse in your managed software. The classes in the FCL are here to facilitate everything from file IO and data structure manipulation to manipulating windows and other GUI elements. The FCL also has advanced classes for creating web and distributed applications.
Before diving headlong into the FCL, I would like to take a little time to address code reuse in general.
Up to this point I have spoken quite a bit about the goals of the .NET Framework, as well as what it means to write managed code and what the CLR does for your software. The Common Language Runtime is the foundation for everything managed, and as such is a very important piece of the .NET puzzle. But in your day to day programming you will spend much more energy discovering, utilizing, and extending the reusable components found in the Framework Class Library.
The Framework Class Library or FCL nothing short of a massive collection of classes, structures, enumerated types and interfaces defined and implemented for reuse in your managed software. The classes in the FCL are here to facilitate everything from file IO and data structure manipulation to manipulating windows and other GUI elements. The FCL also has advanced classes for creating web and distributed applications.
Before diving headlong into the FCL, I would like to take a little time to address code reuse in general.
4.1 Object Oriented Code Reuse
4.1 Object Oriented Code Reuse
Code reuse has been a goal for computer scientist for decades now. Part of the promise of object oriented programming is flexible and advanced code reuse. The CLR is a platform designed from the ground up to be object oriented, and therefore to promote all of the goals of object oriented programming.
Today, most software is written nearly from scratch. The unique logic of most applications can usually be described in several brief statements, and yet most applications include many thousands or millions of lines of custom code to achieve their goals. This can not continue forever.
In the long run the software industry will simply have too much software to write to be writing every application from scratch. Therefore systematic code reuse is a necessity.
Rather than go into a lengthy explanation about why OO and code reuse are difficult-but-necessary, I would like to mention some of the rich features of the CLR that promote object oriented programming.
· The CLR is an object oriented platform from IL up. IL itself includes many instructions for dealing with memory and code as objects.
· The CLR promotes a homogeneous view of types, where every data type in the system, including primitive types, is an object derived from a base object type called System.Object. In this respect literally every data element in your program is an object and has certain consistent properties.
· Managed code has rich support for object oriented constructs such as interfaces, properties, enumerated types and of course classes. All of these code elements are collectively referred to as types when referring to managed code.
· Managed code introduces new object oriented constructs including custom attributes, advanced accessibility, and static constructors (which allow you to initialize types, rather than instances of types) to help fill in the places where other object oriented environments fall short.
· Managed code can make use of pre-built libraries of reusable components. These libraries of components are called managed Assemblies and are the basic building block of binary composeability. (Reusable components are packaged in files called assemblies, however technically even a managed executable is a managed assembly).
· Binary composeability allows your code to use other objects seamlessly without the necessity to have or compile source code from the third party code. (This is largely possible due to the rich descriptions of code maintained in the metadata).
· The CLR has very strong versioning ability. Even though your applications will be composed of many objects published in many different assemblies (files), it will not suffer from versioning problems as new versions of the various pieces are installed on a system. The CLR knows enough about an object to know exactly which version of an object is needed by a particular application.
These features and more build upon and extend previous object oriented platforms. In the long run object oriented platforms like the .NET Framework will change the way applications are built. Moving forward, a larger and larger percentage of the new code that you write will directly relate to the unique aspects of your application. Meanwhile, the standard bits that show up in many applications will be published as reusable and extendible types.
Code reuse has been a goal for computer scientist for decades now. Part of the promise of object oriented programming is flexible and advanced code reuse. The CLR is a platform designed from the ground up to be object oriented, and therefore to promote all of the goals of object oriented programming.
Today, most software is written nearly from scratch. The unique logic of most applications can usually be described in several brief statements, and yet most applications include many thousands or millions of lines of custom code to achieve their goals. This can not continue forever.
In the long run the software industry will simply have too much software to write to be writing every application from scratch. Therefore systematic code reuse is a necessity.
Rather than go into a lengthy explanation about why OO and code reuse are difficult-but-necessary, I would like to mention some of the rich features of the CLR that promote object oriented programming.
· The CLR is an object oriented platform from IL up. IL itself includes many instructions for dealing with memory and code as objects.
· The CLR promotes a homogeneous view of types, where every data type in the system, including primitive types, is an object derived from a base object type called System.Object. In this respect literally every data element in your program is an object and has certain consistent properties.
· Managed code has rich support for object oriented constructs such as interfaces, properties, enumerated types and of course classes. All of these code elements are collectively referred to as types when referring to managed code.
· Managed code introduces new object oriented constructs including custom attributes, advanced accessibility, and static constructors (which allow you to initialize types, rather than instances of types) to help fill in the places where other object oriented environments fall short.
· Managed code can make use of pre-built libraries of reusable components. These libraries of components are called managed Assemblies and are the basic building block of binary composeability. (Reusable components are packaged in files called assemblies, however technically even a managed executable is a managed assembly).
· Binary composeability allows your code to use other objects seamlessly without the necessity to have or compile source code from the third party code. (This is largely possible due to the rich descriptions of code maintained in the metadata).
· The CLR has very strong versioning ability. Even though your applications will be composed of many objects published in many different assemblies (files), it will not suffer from versioning problems as new versions of the various pieces are installed on a system. The CLR knows enough about an object to know exactly which version of an object is needed by a particular application.
These features and more build upon and extend previous object oriented platforms. In the long run object oriented platforms like the .NET Framework will change the way applications are built. Moving forward, a larger and larger percentage of the new code that you write will directly relate to the unique aspects of your application. Meanwhile, the standard bits that show up in many applications will be published as reusable and extendible types.
4.2 The Framework Class Library
4.2 The Framework Class Library
Now that you have a taste of the goals and groundwork laid by the CLR and managed code, let’s taste the fruits that it bears. The Framework Class Library is the first step toward the end solution of component based applications. If you like, you can use it like any other library or API. That is to say that you can write applications that make use of the objects in the FCL to read files, display windows, and do various tasks. But, to exploit the true possibilities, you can extend the FCL towards your applications needs, and then write a very thin layer that is just “application code”. The rest is reusable types and extensions of reusable types.
The FCL is a class library; however it has been designed for extendibility and composeability. This is advanced reuse.
Take, for example, the stream classes in the FCL. The designers of the FCL could have defined file streams and network streams and been done with it. Instead, all stream classes are derived from a base class, called System.IO.Stream. The FCL defines two main kinds of streams: Streams that communicate with devices (such as files, networks and memory), and streams whose devices are other instances of stream derived classes. These abstracted streams can be used for IO formatting, buffering, encryption, data compression, Base-64 encoding, or just about any other kind of data manipulation.
The result of this kind of design is a simple set of classes with a simple set of rules that can be combined in a nearly infinite number of ways to produce the desired affect. Meanwhile, you can derive your own stream classes which can be composed along with the classes that ship with the Framework Class Library. The following sample applications demonstrate streams and FCL composeability in general.
using System;
using System.IO;
class App{
public static void Main(String[] args){
try{
Stream fromStream =
new FileStream(args[0], FileMode.Open, FileAccess.Read);
Stream toStream =
new FileStream(args[1], FileMode.Create, FileAccess.Write);
Byte[] buffer = new Byte[fromStream.Length];
fromStream.Read(buffer, 0, buffer.Length);
toStream.Write(buffer, 0, buffer.Length);
}catch{
Console.WriteLine("Usage: FileToFile [FromFile] [ToFile]");
}
}
}
Figure 4‑1 FileToFile.cs
The code in Figure 4‑1 demonstrates a very simple file copy application. In brief, this application attempts to open a file, read every byte of the file into memory, and then write every byte in memory back out to a new file. If at any point anything fails, the application just prints the usage string for the application (arguably not the best error recovery scheme, but good for an example).
Now look at the following code which includes some minor modifications (marked in red) to the code in Figure 4‑1.
using System;
using System.IO;
using System.Security.Cryptography;
class App{
public static void Main(String[] args){
try{
Stream fromStream =
new FileStream(args[0], FileMode.Open, FileAccess.Read);
Stream toStream =
new FileStream(args[1], FileMode.Create, FileAccess.Write);
Byte[] buffer = new Byte[fromStream.Length];
toStream = new CryptoStream(toStream, new ToBase64Transform(),
CryptoStreamMode.Write);
fromStream.Read(buffer, 0, buffer.Length);
toStream.Write(buffer, 0, buffer.Length);
}catch{
Console.WriteLine("Usage: FileToBase64 [FromFile] [ToFile]");
}
}
}
Figure 4‑2 FileToBase64.cs
The only significant modification to the source code in the previous example is the italicized line of code in Figure 4‑2. This line news-up instances of the CryptoStream (one of the composeable stream classes I have been talking about), and an instance of a helper class called ToBase64Transform. Together these classes turn our toStream variable into a base-64 encoding machine. So now a simple file copy program has become a program with significantly more complex functionality. It will base-64 encode a file and save the results to a second file.
Note: Base-64 encoding is a standard method of data conversion where any binary data is represented as a text-blob consisting only of characters that exist in the printable ASCII character set. Base-64 encoding and decoding is useful for transferring data over the internet and through firewalls, etc.
Here is how the code reuse goal is achieved in this example. Though the details of the FileToBase64 and FileToFile applications are significantly different, the basic idea of both of these applications is largely the same. They both copy data from one file to another. So we achieve our software design goals by making the source code for the two applications 90% the same, even though a great deal of difference lies in the reusable objects selected.
Many classes in the FCL promote this kind of programming, and so should the reusable component classes that you write. To reach this end you must be comfortable with the FCL in general.
Now that you have a taste of the goals and groundwork laid by the CLR and managed code, let’s taste the fruits that it bears. The Framework Class Library is the first step toward the end solution of component based applications. If you like, you can use it like any other library or API. That is to say that you can write applications that make use of the objects in the FCL to read files, display windows, and do various tasks. But, to exploit the true possibilities, you can extend the FCL towards your applications needs, and then write a very thin layer that is just “application code”. The rest is reusable types and extensions of reusable types.
The FCL is a class library; however it has been designed for extendibility and composeability. This is advanced reuse.
Take, for example, the stream classes in the FCL. The designers of the FCL could have defined file streams and network streams and been done with it. Instead, all stream classes are derived from a base class, called System.IO.Stream. The FCL defines two main kinds of streams: Streams that communicate with devices (such as files, networks and memory), and streams whose devices are other instances of stream derived classes. These abstracted streams can be used for IO formatting, buffering, encryption, data compression, Base-64 encoding, or just about any other kind of data manipulation.
The result of this kind of design is a simple set of classes with a simple set of rules that can be combined in a nearly infinite number of ways to produce the desired affect. Meanwhile, you can derive your own stream classes which can be composed along with the classes that ship with the Framework Class Library. The following sample applications demonstrate streams and FCL composeability in general.
using System;
using System.IO;
class App{
public static void Main(String[] args){
try{
Stream fromStream =
new FileStream(args[0], FileMode.Open, FileAccess.Read);
Stream toStream =
new FileStream(args[1], FileMode.Create, FileAccess.Write);
Byte[] buffer = new Byte[fromStream.Length];
fromStream.Read(buffer, 0, buffer.Length);
toStream.Write(buffer, 0, buffer.Length);
}catch{
Console.WriteLine("Usage: FileToFile [FromFile] [ToFile]");
}
}
}
Figure 4‑1 FileToFile.cs
The code in Figure 4‑1 demonstrates a very simple file copy application. In brief, this application attempts to open a file, read every byte of the file into memory, and then write every byte in memory back out to a new file. If at any point anything fails, the application just prints the usage string for the application (arguably not the best error recovery scheme, but good for an example).
Now look at the following code which includes some minor modifications (marked in red) to the code in Figure 4‑1.
using System;
using System.IO;
using System.Security.Cryptography;
class App{
public static void Main(String[] args){
try{
Stream fromStream =
new FileStream(args[0], FileMode.Open, FileAccess.Read);
Stream toStream =
new FileStream(args[1], FileMode.Create, FileAccess.Write);
Byte[] buffer = new Byte[fromStream.Length];
toStream = new CryptoStream(toStream, new ToBase64Transform(),
CryptoStreamMode.Write);
fromStream.Read(buffer, 0, buffer.Length);
toStream.Write(buffer, 0, buffer.Length);
}catch{
Console.WriteLine("Usage: FileToBase64 [FromFile] [ToFile]");
}
}
}
Figure 4‑2 FileToBase64.cs
The only significant modification to the source code in the previous example is the italicized line of code in Figure 4‑2. This line news-up instances of the CryptoStream (one of the composeable stream classes I have been talking about), and an instance of a helper class called ToBase64Transform. Together these classes turn our toStream variable into a base-64 encoding machine. So now a simple file copy program has become a program with significantly more complex functionality. It will base-64 encode a file and save the results to a second file.
Note: Base-64 encoding is a standard method of data conversion where any binary data is represented as a text-blob consisting only of characters that exist in the printable ASCII character set. Base-64 encoding and decoding is useful for transferring data over the internet and through firewalls, etc.
Here is how the code reuse goal is achieved in this example. Though the details of the FileToBase64 and FileToFile applications are significantly different, the basic idea of both of these applications is largely the same. They both copy data from one file to another. So we achieve our software design goals by making the source code for the two applications 90% the same, even though a great deal of difference lies in the reusable objects selected.
Many classes in the FCL promote this kind of programming, and so should the reusable component classes that you write. To reach this end you must be comfortable with the FCL in general.
4.3 Using the FCL
4.3 Using the FCL
“Give a man a fish and you feed him for a day. Teach a man to fish
and you feed him for a lifetime.” The IO stream example in the last section was like me giving you a fish. With the FCL it is much better to learn how to fish, because the Framework Class Library is so expansive and you will use it every time you write managed code. I am going to give you the necessary information for you to learn to learn about the Framework Class Library.
The following is a list of points about the FCL that will help you to learn to use the library.
· The many classes, interfaces, structures and enumerated types in the Framework Class Library are collectively referred to as types.
· The various types in the framework are arranged in a hierarchy of namespaces. This solves the problem of name collisions. But in day-to-day use namespace help programmers to find types that solve a certain kind of problem, and they can help programmers to find more than one type that deal with the same problem (such as IO types that live in the System.IO namespace).
· Namespaces themselves live in a hierarchy and are arranged as words separated by the period “.” character. From the CLR’s point of view a type’s name is its fully qualified name including namespaces. Therefore we may write code that uses a Stream class or a Form class, but in IL these types are represented as System.IO.Stream and System.Windows.Forms.Form respectively.
· Languages such as C# allow you to indicate which namespaces a specific source code file will be using. This way in the source code you can refer to the types in their abbreviated form. The first red source code line in Figure 4‑2 is an example of the using statement in C#. I added this line to the code to indicate to the compiler that the sources included types found in the System.Security.Cryptography namespace of the FCL. In this example these types were the CryptoStream, ToBase64Transform and CryptoStreamMode types.
· The System namespace is a good place to look for types that are useful across a wide number of different types of applications.
· All types must have a base class (including types that you define in your). The exception to this rule is the System.Object type which is the base type for all types in the system. (If you create a class that does not explicitly declare a base class then the compiler implicitly defines its base class to be Object).
· The facts in this list plus comfort with the .NET Framework SDK Documentation will really bootstrap your skills with managed code.
“Give a man a fish and you feed him for a day. Teach a man to fish
and you feed him for a lifetime.” The IO stream example in the last section was like me giving you a fish. With the FCL it is much better to learn how to fish, because the Framework Class Library is so expansive and you will use it every time you write managed code. I am going to give you the necessary information for you to learn to learn about the Framework Class Library.
The following is a list of points about the FCL that will help you to learn to use the library.
· The many classes, interfaces, structures and enumerated types in the Framework Class Library are collectively referred to as types.
· The various types in the framework are arranged in a hierarchy of namespaces. This solves the problem of name collisions. But in day-to-day use namespace help programmers to find types that solve a certain kind of problem, and they can help programmers to find more than one type that deal with the same problem (such as IO types that live in the System.IO namespace).
· Namespaces themselves live in a hierarchy and are arranged as words separated by the period “.” character. From the CLR’s point of view a type’s name is its fully qualified name including namespaces. Therefore we may write code that uses a Stream class or a Form class, but in IL these types are represented as System.IO.Stream and System.Windows.Forms.Form respectively.
· Languages such as C# allow you to indicate which namespaces a specific source code file will be using. This way in the source code you can refer to the types in their abbreviated form. The first red source code line in Figure 4‑2 is an example of the using statement in C#. I added this line to the code to indicate to the compiler that the sources included types found in the System.Security.Cryptography namespace of the FCL. In this example these types were the CryptoStream, ToBase64Transform and CryptoStreamMode types.
· The System namespace is a good place to look for types that are useful across a wide number of different types of applications.
· All types must have a base class (including types that you define in your). The exception to this rule is the System.Object type which is the base type for all types in the system. (If you create a class that does not explicitly declare a base class then the compiler implicitly defines its base class to be Object).
· The facts in this list plus comfort with the .NET Framework SDK Documentation will really bootstrap your skills with managed code.
4.4 The .NET Framework SDK Documentation
4.4 The .NET Framework SDK Documentation
When you install Visual Studio .NET or the .NET Framework SDK you should make a point of installing the full documentation for the SDK. This is important. The SDK Documentation includes a wealth of great information. In fact, there is so much information in the docs that it can be overwhelming, so I am going to point out a limited set of topics that you should read.
The first topic in the table of contents for the .NET Framework SDK docs is called Getting Started with the .NET Framework->Overview of the .NET Framework. It is a short read and you should read it first. It is not nearly as detailed as this tutorial, but it will get you started with the SDK docs, and point you in the direction of other interesting topics.
The second place to look is under .NET Framework Reference->.NET Framework Class Library. This is the beginning of the reference documentation for all of the reusable types contained in the FCL. The references are arranged by namespace, and you should read the starting topic .NET Framework Class Library just to familiarize yourself with the namespaces in the FCL.
All of the reading I have suggested will most likely take less than a couple of hours. Then after this point you need only to refer to the documentation for one type at a time.
When you install Visual Studio .NET or the .NET Framework SDK you should make a point of installing the full documentation for the SDK. This is important. The SDK Documentation includes a wealth of great information. In fact, there is so much information in the docs that it can be overwhelming, so I am going to point out a limited set of topics that you should read.
The first topic in the table of contents for the .NET Framework SDK docs is called Getting Started with the .NET Framework->Overview of the .NET Framework. It is a short read and you should read it first. It is not nearly as detailed as this tutorial, but it will get you started with the SDK docs, and point you in the direction of other interesting topics.
The second place to look is under .NET Framework Reference->.NET Framework Class Library. This is the beginning of the reference documentation for all of the reusable types contained in the FCL. The references are arranged by namespace, and you should read the starting topic .NET Framework Class Library just to familiarize yourself with the namespaces in the FCL.
All of the reading I have suggested will most likely take less than a couple of hours. Then after this point you need only to refer to the documentation for one type at a time.
4.5 Using FCL Documentation for Types
4.5 Using FCL Documentation for Types
Using the SDK documentation for a given type will likely be a daily or even hourly event when you first start writing managed code. So a practical exposure to the format can be helpful.
The first time that you use a new type you should look up the type in the reference documentation. Enter the name of the type (for example, System.Windows.Forms.Form or just Form) into the index tab of the documentation and select the topic for that type. The starting topic for a type can be very helpful and you should read it entirely. Then as you use the different member variables and member methods you can read their topics as needed. Here is an example of a topic from the FCL reference documentation.
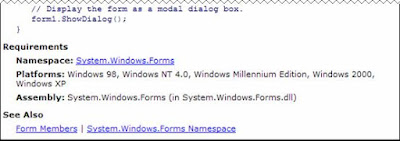
Figure 4‑3 Sample SDK Reference Topic
Starting at the top of Figure 4‑3 and reading to the bottom, here are some noteworthy parts of the reference docs for a type.
· The top indicates the name of the type and the type of the type. In this example the name is Form and the type is a class (as opposed to a structure or interface, etc.).
· Following this is an abbreviated hierarchy indicating the derivation heritage from System.Object on up to the topic type and sometimes beyond if the type is a base class for other classes in the FCL.
· The Remarks section in any topic is likely to include a detailed description of the purpose of a type, as well as how to use it and links to companion types in the FCL. In the case of Figure 4‑3 the Remarks section included so much information that I had to excerpt it out of the figure so that it would fit on a single page in this tutorial.
· Many type topics in the FCL reference documentation include Example sections complete with source-code and a brief description. This can be one of the most helpful parts of the documentation! If you are having trouble conceptualizing the use of a particular type, just cut and paste the sample code into a quick C# project and try it out directly. Again, the source code for the Form topic was lengthy enough that I excerpted out the bulk of the source-code so that Figure 4‑3 would fit on a single page.
· The Requirements section of the topic is often one of the most important and commonly referenced parts of the reference documentation. One reason for this is that it includes the namespace of the type. In this example the Form type is in the System.Windows.Forms namespace. The namespace listed at the bottom of the help topic tells you what using statement you should add near the top of your source-code module. If you are using the Form type you would commonly include this line of code in your .cs file.
using System.Windows.Forms;
· Another key piece of information in the Requirements section of a type’s help topic is the assembly in which the type exists. All managed types must exist in a file (or group of files) known as an assembly. (In fact even a simple C# executable is technically a managed assembly). The FCL is published as a collection of dozens of assemblies. When one assembly references a type in another assembly, the compiler needs to know about the referenced assembly. This means that if your code references a type in the FCL, then you need to make sure that your project references that type’s assembly.
o If you are using the command line compiler, the /r compiler switch is used to indicate an assembly reference.
o If you are using the Visual Studio .NET environment to build your projects you can add a referenced assembly to a project using the add reference menu item.
· At least two important pieces of information are included in the See Also section of a FCL type reference topic. These are the links to the topics for the types members and the types namespace. The type members topic describes in brief all of the member methods, constructors, properties and member fields of a type. These topics detail what a type can do. The namespace topic for a type is a great way to find related types in the FCL. If you know that you know one class that you need, you can link to its namespace topic and find other classes that are likely to be helpful for your task.
It may seem strange, at first, to approach the reference documentation with the rigor expressed in the preceding bullets, but if you do you will master the Framework Class Library in no time.
Exercise 4‑1 Compile and Test Sample Code
1. As you have seen in this section many SDK topics include a fair amount of sample code. You should be comfortable cutting and pasting this code into your own projects to become familiar with various types.
2. Using the SDK documentation, search for the starting topic for the System.Windows.Forms.Form class. Read this help topic top to bottom.
3. Now create a new .cs file and cut and paste the sample source code from the SDK topic into your new source code file.
1. Hint: You will need to create a class with a static Main() method for an entry point. Your main method can be comprised of the sample code, or it can call the function in the sample code.
4. Build the new file, either with the command line compiler or the Visual Studio .NET IDE.
Exercise 4‑2 Create Base64toFile.cs
1. The source code in Figure 4‑2 implements a command line utility that converts a file to its base-64 representation. In this exercise you will modify these sources to create a utility that converts base-64 data back to its original form.
2. Here are some tips.
1. The CryptoStream will be the fromStream rather than the toStream in the new application.
2. You will use the Read element of the CryptoStreamMode enumeration rather than the Write element when newing up an instance of the CryptoStream.
3. You will use the FromBase64Transform helper type rather than the ToBase64Transform type.
3. Compile and test the new application.
Using the SDK documentation for a given type will likely be a daily or even hourly event when you first start writing managed code. So a practical exposure to the format can be helpful.
The first time that you use a new type you should look up the type in the reference documentation. Enter the name of the type (for example, System.Windows.Forms.Form or just Form) into the index tab of the documentation and select the topic for that type. The starting topic for a type can be very helpful and you should read it entirely. Then as you use the different member variables and member methods you can read their topics as needed. Here is an example of a topic from the FCL reference documentation.



Figure 4‑3 Sample SDK Reference Topic
Starting at the top of Figure 4‑3 and reading to the bottom, here are some noteworthy parts of the reference docs for a type.
· The top indicates the name of the type and the type of the type. In this example the name is Form and the type is a class (as opposed to a structure or interface, etc.).
· Following this is an abbreviated hierarchy indicating the derivation heritage from System.Object on up to the topic type and sometimes beyond if the type is a base class for other classes in the FCL.
· The Remarks section in any topic is likely to include a detailed description of the purpose of a type, as well as how to use it and links to companion types in the FCL. In the case of Figure 4‑3 the Remarks section included so much information that I had to excerpt it out of the figure so that it would fit on a single page in this tutorial.
· Many type topics in the FCL reference documentation include Example sections complete with source-code and a brief description. This can be one of the most helpful parts of the documentation! If you are having trouble conceptualizing the use of a particular type, just cut and paste the sample code into a quick C# project and try it out directly. Again, the source code for the Form topic was lengthy enough that I excerpted out the bulk of the source-code so that Figure 4‑3 would fit on a single page.
· The Requirements section of the topic is often one of the most important and commonly referenced parts of the reference documentation. One reason for this is that it includes the namespace of the type. In this example the Form type is in the System.Windows.Forms namespace. The namespace listed at the bottom of the help topic tells you what using statement you should add near the top of your source-code module. If you are using the Form type you would commonly include this line of code in your .cs file.
using System.Windows.Forms;
· Another key piece of information in the Requirements section of a type’s help topic is the assembly in which the type exists. All managed types must exist in a file (or group of files) known as an assembly. (In fact even a simple C# executable is technically a managed assembly). The FCL is published as a collection of dozens of assemblies. When one assembly references a type in another assembly, the compiler needs to know about the referenced assembly. This means that if your code references a type in the FCL, then you need to make sure that your project references that type’s assembly.
o If you are using the command line compiler, the /r compiler switch is used to indicate an assembly reference.
o If you are using the Visual Studio .NET environment to build your projects you can add a referenced assembly to a project using the add reference menu item.
· At least two important pieces of information are included in the See Also section of a FCL type reference topic. These are the links to the topics for the types members and the types namespace. The type members topic describes in brief all of the member methods, constructors, properties and member fields of a type. These topics detail what a type can do. The namespace topic for a type is a great way to find related types in the FCL. If you know that you know one class that you need, you can link to its namespace topic and find other classes that are likely to be helpful for your task.
It may seem strange, at first, to approach the reference documentation with the rigor expressed in the preceding bullets, but if you do you will master the Framework Class Library in no time.
Exercise 4‑1 Compile and Test Sample Code
1. As you have seen in this section many SDK topics include a fair amount of sample code. You should be comfortable cutting and pasting this code into your own projects to become familiar with various types.
2. Using the SDK documentation, search for the starting topic for the System.Windows.Forms.Form class. Read this help topic top to bottom.
3. Now create a new .cs file and cut and paste the sample source code from the SDK topic into your new source code file.
1. Hint: You will need to create a class with a static Main() method for an entry point. Your main method can be comprised of the sample code, or it can call the function in the sample code.
4. Build the new file, either with the command line compiler or the Visual Studio .NET IDE.
Exercise 4‑2 Create Base64toFile.cs
1. The source code in Figure 4‑2 implements a command line utility that converts a file to its base-64 representation. In this exercise you will modify these sources to create a utility that converts base-64 data back to its original form.
2. Here are some tips.
1. The CryptoStream will be the fromStream rather than the toStream in the new application.
2. You will use the Read element of the CryptoStreamMode enumeration rather than the Write element when newing up an instance of the CryptoStream.
3. You will use the FromBase64Transform helper type rather than the ToBase64Transform type.
3. Compile and test the new application.
5 Using the .NET Framework
5 Using the .NET Framework
We have covered a lot in these past few pages. If you are starting with some previous knowledge of C# or some other .NET related technologies, then this document has most likely helped to solidify your grasp on the topic. But, if this tutorial is your first exposure to the .NET Framework then you have just absorbed a great deal of foundation information.
In this section I would like to rehash the “big picture” and then discuss some of the applications of this technology.
We have covered a lot in these past few pages. If you are starting with some previous knowledge of C# or some other .NET related technologies, then this document has most likely helped to solidify your grasp on the topic. But, if this tutorial is your first exposure to the .NET Framework then you have just absorbed a great deal of foundation information.
In this section I would like to rehash the “big picture” and then discuss some of the applications of this technology.
Friday, March 13, 2009
5.1 The .NET Framework: Big Picture
5.1 The .NET Framework: Big Picture

Figure 5‑1 The .NET Framework in Context
Looking at Figure 5‑1 we see the lifespan of managed code from source code to execution. You write the source code. Your sources take advantage of features of the CLR as well as the reusable types in the FCL. You compile your sources with a compiler that supports the .NET Framework. The compiler turns your sources into an executable file consisting of IL and metadata.
When a user runs your executable the system loads the CLR into your process’ address space and the CLR JIT-compiles your IL (and metadata) into machine code and executes it. Meanwhile, your code references pre-jitted types in the FCL (as well as other reusable component libraries) and does its job, all the time being fully managed by the Common Language Runtime.
Note: This is the basic execution scenario of managed code. It is also possible for unmanaged software to host the CLR. In this case, the unmanaged application sits between the CLR and the operating system itself. Internet Explorer and Internet Information Services are two examples of existing Runtime Hosts; however any application can be designed to host the runtime.
In Figure 5‑1 the FCL and the CLR are really the pieces that make up the .NET Framework. Everything else is underlying OS, your code, and tools.
Once you are comfortable with the breadth of what the .NET Framework does, then you can begin to see how this technology is applied.

Figure 5‑1 The .NET Framework in Context
Looking at Figure 5‑1 we see the lifespan of managed code from source code to execution. You write the source code. Your sources take advantage of features of the CLR as well as the reusable types in the FCL. You compile your sources with a compiler that supports the .NET Framework. The compiler turns your sources into an executable file consisting of IL and metadata.
When a user runs your executable the system loads the CLR into your process’ address space and the CLR JIT-compiles your IL (and metadata) into machine code and executes it. Meanwhile, your code references pre-jitted types in the FCL (as well as other reusable component libraries) and does its job, all the time being fully managed by the Common Language Runtime.
Note: This is the basic execution scenario of managed code. It is also possible for unmanaged software to host the CLR. In this case, the unmanaged application sits between the CLR and the operating system itself. Internet Explorer and Internet Information Services are two examples of existing Runtime Hosts; however any application can be designed to host the runtime.
In Figure 5‑1 the FCL and the CLR are really the pieces that make up the .NET Framework. Everything else is underlying OS, your code, and tools.
Once you are comfortable with the breadth of what the .NET Framework does, then you can begin to see how this technology is applied.
5.2 .NET Application Scenarios
5.2 .NET Application Scenarios
Managed code can be used to develop a variety of different kinds of software. First, it is worth mentioning that most existing styles of software can be developed using managed code. This includes console or command-line applications as well as GUI or windowed applications. Here is a list of the types of applications that can be developed using C# or any other language that targets the .NET Framework.
· GUI Applications – Managed applications that present a graphical interface to the user are referred to as Windows Forms applications. These programs can have the typical buttons, menus, drag-and-drop, and other features that are expected from GUI applications.
· Console Applications – Managed code is inherently operating system agnostic. As such, it is necessary that both of the major styles of user interface are supported by managed code. Therefore you can write managed console applications. This can be useful for writing managed versions of control-scripts and other batch-able commands.
· Active Web Applications – Managed code can be used to create web pages that are generated programmatically as the result of running software (as opposed to static html). These applications are referred to as Web Form applications. Web Forms are the managed answer to technologies such as CGI, ISAPI, and JSP. You write your managed code using C# much like a typical application, however it executes on the server side (by a web-server that hosts the CLR, and therefore hosts managed code). This hosting component is called ASP.NET and allows your applications to present their UI as web-pages.
· Web service applications – Web services are software components that perform a task in a distributed manner. In a sense, a web-service is like an active web-page, where the client is another piece of software, rather than a human user using a browser. Web services use standard protocols such as SOAP and XML to communicate any kind of data between machines across the internet. The .NET Framework can easily be used to create and expose web service applications on the Internet. It is also very easy to create web-service client software using C# or any other .NET Language. See www.XMethods.com for an example of the types of objects or algorithms that are exposed as web-services.
· Scripted Components – It is common for major applications such as Microsoft Excel or CodeWrite to include macro languages that make it possible to customize the functionality of the application. In fact some applications or application suites (such as Microsoft Office) have such advanced scripting abilities that you can develop complete applications in their macro environment. Moving forward, managed code will be the vessel for all scripting for applications running on Windows (and hopefully other operating systems as well). The CLR can be hosted in any application whether the application is managed or unmanaged. This allows typical managed code to become the “scripting language” for the application. (Of course with managed code all scripts will be JIT compiled, and execute at full speed, but this is just the icing on the cake). Now if you become comfortable with C# or some other language that targets the .NET Framework, you will already know the macro language for the applications that you use. You can also develop applications that host the .NET Framework so that your applications are scriptable using managed code.
· Other miscellaneous applications – Managed code can be used to develop NT services, legacy ActiveX and COM controls, as well as a handful of other types of applications. However, the really exciting application types are the ones that we covered in the previous bullets.

Figure 5‑2 Managed Code in an Internet-Distributed World
Remember Figure 1‑1? It showed software in a highly distributed environment. Figure 5‑2 takes a cross-section of Figure 1‑1 and describes where managed code fits into the picture.
Regardless of where the application runs, with managed code developers like you and me are able to
· use the programming language that they prefer,
· use objects and components created in other (.NET) languages,
· create a variety of application types using tools with which they are comfortable
· and build on knowledge gained in other, often largely dissimilar, projects because so much of the groundwork is based in the same features (the CLR, managed code, IL, the FCL, etc.).
Let’s dive headlong into a real managed application just for fun.
Managed code can be used to develop a variety of different kinds of software. First, it is worth mentioning that most existing styles of software can be developed using managed code. This includes console or command-line applications as well as GUI or windowed applications. Here is a list of the types of applications that can be developed using C# or any other language that targets the .NET Framework.
· GUI Applications – Managed applications that present a graphical interface to the user are referred to as Windows Forms applications. These programs can have the typical buttons, menus, drag-and-drop, and other features that are expected from GUI applications.
· Console Applications – Managed code is inherently operating system agnostic. As such, it is necessary that both of the major styles of user interface are supported by managed code. Therefore you can write managed console applications. This can be useful for writing managed versions of control-scripts and other batch-able commands.
· Active Web Applications – Managed code can be used to create web pages that are generated programmatically as the result of running software (as opposed to static html). These applications are referred to as Web Form applications. Web Forms are the managed answer to technologies such as CGI, ISAPI, and JSP. You write your managed code using C# much like a typical application, however it executes on the server side (by a web-server that hosts the CLR, and therefore hosts managed code). This hosting component is called ASP.NET and allows your applications to present their UI as web-pages.
· Web service applications – Web services are software components that perform a task in a distributed manner. In a sense, a web-service is like an active web-page, where the client is another piece of software, rather than a human user using a browser. Web services use standard protocols such as SOAP and XML to communicate any kind of data between machines across the internet. The .NET Framework can easily be used to create and expose web service applications on the Internet. It is also very easy to create web-service client software using C# or any other .NET Language. See www.XMethods.com for an example of the types of objects or algorithms that are exposed as web-services.
· Scripted Components – It is common for major applications such as Microsoft Excel or CodeWrite to include macro languages that make it possible to customize the functionality of the application. In fact some applications or application suites (such as Microsoft Office) have such advanced scripting abilities that you can develop complete applications in their macro environment. Moving forward, managed code will be the vessel for all scripting for applications running on Windows (and hopefully other operating systems as well). The CLR can be hosted in any application whether the application is managed or unmanaged. This allows typical managed code to become the “scripting language” for the application. (Of course with managed code all scripts will be JIT compiled, and execute at full speed, but this is just the icing on the cake). Now if you become comfortable with C# or some other language that targets the .NET Framework, you will already know the macro language for the applications that you use. You can also develop applications that host the .NET Framework so that your applications are scriptable using managed code.
· Other miscellaneous applications – Managed code can be used to develop NT services, legacy ActiveX and COM controls, as well as a handful of other types of applications. However, the really exciting application types are the ones that we covered in the previous bullets.

Figure 5‑2 Managed Code in an Internet-Distributed World
Remember Figure 1‑1? It showed software in a highly distributed environment. Figure 5‑2 takes a cross-section of Figure 1‑1 and describes where managed code fits into the picture.
Regardless of where the application runs, with managed code developers like you and me are able to
· use the programming language that they prefer,
· use objects and components created in other (.NET) languages,
· create a variety of application types using tools with which they are comfortable
· and build on knowledge gained in other, often largely dissimilar, projects because so much of the groundwork is based in the same features (the CLR, managed code, IL, the FCL, etc.).
Let’s dive headlong into a real managed application just for fun.
5.3 Draw.aspx Web Applications
5.3 Draw.aspx Web Applications
I am just about to finish this tutorial. I have given you a couple of code samples to chew on, but they are pretty simple in nature. Now I would like to present you with a more substantial application, just so that you can see C#, the CLR, the FCL, and .NET in general in action.
This program is called Draw.aspx and is a simple Draw Poker game that runs as a web forms application. Remember that web forms applications run on the server side, and present their UI to the browser as HTML. In fact, the Draw.aspx game can be played by any common browser running on any common OS in the world. The Draw.aspx program must be hosted, however, on a machine running Internet Information Services (which is the only web server at the time of this writing that hosts managed code).
Perhaps I should apologize. Web form applications are a fairly advanced type of managed application (which I cover in detail in several tutorials in this series). So it could be argued that you would be better served with a more typical style of application for your first submersion into C#. But, I am guilty of being excited by the technology, and I wanted your introduction sample application to show off some cool abilities.
In general, I did try to keep Draw.aspx fairly simple. Like all web-sites in general, web form applications must manage state transitions very rigidly. Draw.aspx is so simple that it really only runs in two states. These are the state where a user begins a deal and the state where the user selects cards to hold then draws. The Draw.aspx game is so simple, in fact, that it has no notion of betting, scoring, winning or losing of any kind.
What it does show, however, are some very advanced features. First, you will see that it includes image and control manipulation on an active web page. Second, Draw.aspx shows how the FCL web forms classes adjust their HTML output as needed to support the various browsers. You will see in the Draw.aspx sources a solid introduction to C#, object oriented programming, the FCL collection classes and other utility components, as well as general development in the .NET environment. If you spend some time groveling around in the sources for this sample you will come away with some useful nuggets of information.
Enjoy Draw.aspx. Enjoy C# and the .NET Framework. Have fun, and I will see you in the next tutorial!
I am just about to finish this tutorial. I have given you a couple of code samples to chew on, but they are pretty simple in nature. Now I would like to present you with a more substantial application, just so that you can see C#, the CLR, the FCL, and .NET in general in action.
This program is called Draw.aspx and is a simple Draw Poker game that runs as a web forms application. Remember that web forms applications run on the server side, and present their UI to the browser as HTML. In fact, the Draw.aspx game can be played by any common browser running on any common OS in the world. The Draw.aspx program must be hosted, however, on a machine running Internet Information Services (which is the only web server at the time of this writing that hosts managed code).
Perhaps I should apologize. Web form applications are a fairly advanced type of managed application (which I cover in detail in several tutorials in this series). So it could be argued that you would be better served with a more typical style of application for your first submersion into C#. But, I am guilty of being excited by the technology, and I wanted your introduction sample application to show off some cool abilities.
In general, I did try to keep Draw.aspx fairly simple. Like all web-sites in general, web form applications must manage state transitions very rigidly. Draw.aspx is so simple that it really only runs in two states. These are the state where a user begins a deal and the state where the user selects cards to hold then draws. The Draw.aspx game is so simple, in fact, that it has no notion of betting, scoring, winning or losing of any kind.
What it does show, however, are some very advanced features. First, you will see that it includes image and control manipulation on an active web page. Second, Draw.aspx shows how the FCL web forms classes adjust their HTML output as needed to support the various browsers. You will see in the Draw.aspx sources a solid introduction to C#, object oriented programming, the FCL collection classes and other utility components, as well as general development in the .NET environment. If you spend some time groveling around in the sources for this sample you will come away with some useful nuggets of information.
Enjoy Draw.aspx. Enjoy C# and the .NET Framework. Have fun, and I will see you in the next tutorial!
Input/Output with files
Input/Output with files
C++ provides the following classes to perform output and input of characters to/from files:
* ofstream: Stream class to write on files
* ifstream: Stream class to read from files
* fstream: Stream class to both read and write from/to files.
These classes are derived directly or indirectly from the classes istream, and ostream. We have already used objects whose types were these classes: cin is an object of class istream and cout is an object of class ostream. Therfore, we have already been using classes that are related to our file streams. And in fact, we can use our file streams the same way we are already used to use cin and cout, with the only difference that we have to associate these streams with physical files. Let's see an example:
// basic file operations
#include
#include
using namespace std;
int main () {
ofstream myfile;
myfile.open ("example.txt");
myfile << "Writing this to a file.\n";
myfile.close();
return 0;
}
[file example.txt]
Writing this to a file
This code creates a file called example.txt and inserts a sentence into it in the same way we are used to do with cout, but using the file stream myfile instead.
But let's go step by step:
Open a file
The first operation generally performed on an object of one of these classes is to associate it to a real file. This procedure is known as to open a file. An open file is represented within a program by a stream object (an instantiation of one of these classes, in the previous example this was myfile) and any input or output operation performed on this stream object will be applied to the physical file associated to it.
In order to open a file with a stream object we use its member function open():
open (filename, mode);
Where filename is a null-terminated character sequence of type const char * (the same type that string literals have) representing the name of the file to be opened, and mode is an optional parameter with a combination of the following flags:
All these flags can be combined using the bitwise operator OR (|). For example, if we want to open the file example.bin in binary mode to add data we could do it by the following call to member function open():
ofstream myfile;
myfile.open ("example.bin", ios::out | ios::app | ios::binary);
Each one of the open() member functions of the classes ofstream, ifstream and fstream has a default mode that is used if the file is opened without a second argument:
For ifstream and ofstream classes, ios::in and ios::out are automatically and respectively assumed, even if a mode that does not include them is passed as second argument to the open() member function.
The default value is only applied if the function is called without specifying any value for the mode parameter. If the function is called with any value in that parameter the default mode is overridden, not combined.
File streams opened in binary mode perform input and output operations independently of any format considerations. Non-binary files are known as text files, and some translations may occur due to formatting of some special characters (like newline and carriage return characters).
Since the first task that is performed on a file stream object is generally to open a file, these three classes include a constructor that automatically calls the open() member function and has the exact same parameters as this member. Therefore, we could also have declared the previous myfile object and conducted the same opening operation in our previous example by writing:
ofstream myfile ("example.bin", ios::out | ios::app | ios::binary);
Combining object construction and stream opening in a single statement. Both forms to open a file are valid and equivalent.
To check if a file stream was successful opening a file, you can do it by calling to member is_open() with no arguments. This member function returns a bool value of true in the case that indeed the stream object is associated with an open file, or false otherwise:
if (myfile.is_open()) { /* ok, proceed with output */ }
Closing a file
When we are finished with our input and output operations on a file we shall close it so that its resources become available again. In order to do that we have to call the stream's member function close(). This member function takes no parameters, and what it does is to flush the associated buffers and close the file:
myfile.close();
Once this member function is called, the stream object can be used to open another file, and the file is available again to be opened by other processes.
In case that an object is destructed while still associated with an open file, the destructor automatically calls the member function close().
Text files
Text file streams are those where we do not include the ios::binary flag in their opening mode. These files are designed to store text and thus all values that we input or output from/to them can suffer some formatting transformations, which do not necessarily correspond to their literal binary value.
Data output operations on text files are performed in the same way we operated with cout:
// writing on a text file
#include
#include
using namespace std;
int main () {
ofstream myfile ("example.txt");
if (myfile.is_open())
{
myfile << "This is a line.\n";
myfile << "This is another line.\n";
myfile.close();
}
else cout << "Unable to open file";
return 0;
}
[file example.txt]
This is a line.
This is another line.
Data input from a file can also be performed in the same way that we did with cin:
// reading a text file
#include
#include
#include
using namespace std;
int main () {
string line;
ifstream myfile ("example.txt");
if (myfile.is_open())
{
while (! myfile.eof() )
{
getline (myfile,line);
cout << line << endl;
}
myfile.close();
}
else cout << "Unable to open file";
return 0;
}
This is a line.
This is another line.
This last example reads a text file and prints out its content on the screen. Notice how we have used a new member function, called eof() that returns true in the case that the end of the file has been reached. We have created a while loop that finishes when indeed myfile.eof() becomes true (i.e., the end of the file has been reached).
Checking state flags
In addition to eof(), which checks if the end of file has been reached, other member functions exist to check the state of a stream (all of them return a bool value):
bad()
Returns true if a reading or writing operation fails. For example in the case that we try to write to a file that is not open for writing or if the device where we try to write has no space left.
fail()
Returns true in the same cases as bad(), but also in the case that a format error happens, like when an alphabetical character is extracted when we are trying to read an integer number.
eof()
Returns true if a file open for reading has reached the end.
good()
It is the most generic state flag: it returns false in the same cases in which calling any of the previous functions would return true.
In order to reset the state flags checked by any of these member functions we have just seen we can use the member function clear(), which takes no parameters.
get and put stream pointers
All i/o streams objects have, at least, one internal stream pointer:
ifstream, like istream, has a pointer known as the get pointer that points to the element to be read in the next input operation.
ofstream, like ostream, has a pointer known as the put pointer that points to the location where the next element has to be written.
Finally, fstream, inherits both, the get and the put pointers, from iostream (which is itself derived from both istream and ostream).
These internal stream pointers that point to the reading or writing locations within a stream can be manipulated using the following member functions:
tellg() and tellp()
These two member functions have no parameters and return a value of the member type pos_type, which is an integer data type representing the current position of the get stream pointer (in the case of tellg) or the put stream pointer (in the case of tellp).
seekg() and seekp()
These functions allow us to change the position of the get and put stream pointers. Both functions are overloaded with two different prototypes. The first prototype is:
seekg ( position );
seekp ( position );
Using this prototype the stream pointer is changed to the absolute position position (counting from the beginning of the file). The type for this parameter is the same as the one returned by functions tellg and tellp: the member type pos_type, which is an integer value.
The other prototype for these functions is:
seekg ( offset, direction );
seekp ( offset, direction );
Using this prototype, the position of the get or put pointer is set to an offset value relative to some specific point determined by the parameter direction. offset is of the member type off_type, which is also an integer type. And direction is of type seekdir, which is an enumerated type (enum) that determines the point from where offset is counted from, and that can take any of the following values:
The following example uses the member functions we have just seen to obtain the size of a file:
// obtaining file size
#include
#include
using namespace std;
int main () {
long begin,end;
ifstream myfile ("example.txt");
begin = myfile.tellg();
myfile.seekg (0, ios::end);
end = myfile.tellg();
myfile.close();
cout << "size is: " << (end-begin) << " bytes.\n";
return 0;
}
size is: 40 bytes.
Binary files
In binary files, to input and output data with the extraction and insertion operators (<< and >>) and functions like getline is not efficient, since we do not need to format any data, and data may not use the separation codes used by text files to separate elements (like space, newline, etc...).
File streams include two member functions specifically designed to input and output binary data sequentially: write and read. The first one (write) is a member function of ostream inherited by ofstream. And read is a member function of istream that is inherited by ifstream. Objects of class fstream have both members. Their prototypes are:
write ( memory_block, size );
read ( memory_block, size );
Where memory_block is of type "pointer to char" (char*), and represents the address of an array of bytes where the read data elements are stored or from where the data elements to be written are taken. The size parameter is an integer value that specifies the number of characters to be read or written from/to the memory block.
// reading a complete binary file
#include
#include
using namespace std;
ifstream::pos_type size;
char * memblock;
int main () {
ifstream file ("example.bin", ios::in|ios::binary|ios::ate);
if (file.is_open())
{
size = file.tellg();
memblock = new char [size];
file.seekg (0, ios::beg);
file.read (memblock, size);
file.close();
cout << "the complete file content is in memory";
delete[] memblock;
}
else cout << "Unable to open file";
return 0;
}
the complete file content is in memory
In this example the entire file is read and stored in a memory block. Let's examine how this is done:
First, the file is open with the ios::ate flag, which means that the get pointer will be positioned at the end of the file. This way, when we call to member tellg(), we will directly obtain the size of the file. Notice the type we have used to declare variable size:
ifstream::pos_type size;
ifstream::pos_type is a specific type used for buffer and file positioning and is the type returned by file.tellg(). This type is defined as an integer type, therefore we can conduct on it the same operations we conduct on any other integer value, and can safely be converted to another integer type large enough to contain the size of the file. For a file with a size under 2GB we could use int:
int size;
size = (int) file.tellg();
Once we have obtained the size of the file, we request the allocation of a memory block large enough to hold the entire file:
memblock = new char[size];
Right after that, we proceed to set the get pointer at the beginning of the file (remember that we opened the file with this pointer at the end), then read the entire file, and finally close it:
file.seekg (0, ios::beg);
file.read (memblock, size);
file.close();
At this point we could operate with the data obtained from the file. Our program simply announces that the content of the file is in memory and then terminates.
Buffers and Synchronization
When we operate with file streams, these are associated to an internal buffer of type streambuf. This buffer is a memory block that acts as an intermediary between the stream and the physical file. For example, with an ofstream, each time the member function put (which writes a single character) is called, the character is not written directly to the physical file with which the stream is associated. Instead of that, the character is inserted in that stream's intermediate buffer.
When the buffer is flushed, all the data contained in it is written to the physical medium (if it is an output stream) or simply freed (if it is an input stream). This process is called synchronization and takes place under any of the following circumstances:
* When the file is closed: before closing a file all buffers that have not yet been flushed are synchronized and all pending data is written or read to the physical medium.
* When the buffer is full: Buffers have a certain size. When the buffer is full it is automatically synchronized.
* Explicitly, with manipulators: When certain manipulators are used on streams, an explicit synchronization takes place. These manipulators are: flush and endl.
* Explicitly, with member function sync(): Calling stream's member function sync(), which takes no parameters, causes an immediate synchronization. This function returns an int value equal to -1 if the stream has no associated buffer or in case of failure. Otherwise (if the stream buffer was successfully synchronized) it returns 0.
C++ provides the following classes to perform output and input of characters to/from files:
* ofstream: Stream class to write on files
* ifstream: Stream class to read from files
* fstream: Stream class to both read and write from/to files.
These classes are derived directly or indirectly from the classes istream, and ostream. We have already used objects whose types were these classes: cin is an object of class istream and cout is an object of class ostream. Therfore, we have already been using classes that are related to our file streams. And in fact, we can use our file streams the same way we are already used to use cin and cout, with the only difference that we have to associate these streams with physical files. Let's see an example:
// basic file operations
#include
#include
using namespace std;
int main () {
ofstream myfile;
myfile.open ("example.txt");
myfile << "Writing this to a file.\n";
myfile.close();
return 0;
}
[file example.txt]
Writing this to a file
This code creates a file called example.txt and inserts a sentence into it in the same way we are used to do with cout, but using the file stream myfile instead.
But let's go step by step:
Open a file
The first operation generally performed on an object of one of these classes is to associate it to a real file. This procedure is known as to open a file. An open file is represented within a program by a stream object (an instantiation of one of these classes, in the previous example this was myfile) and any input or output operation performed on this stream object will be applied to the physical file associated to it.
In order to open a file with a stream object we use its member function open():
open (filename, mode);
Where filename is a null-terminated character sequence of type const char * (the same type that string literals have) representing the name of the file to be opened, and mode is an optional parameter with a combination of the following flags:
| ios::in | Open for input operations. |
| ios::out | Open for output operations. |
| ios::binary | Open in binary mode. |
| ios::ate | Set the initial position at the end of the file. If this flag is not set to any value, the initial position is the beginning of the file. |
| ios::app | All output operations are performed at the end of the file, appending the content to the current content of the file. This flag can only be used in streams open for output-only operations. |
| ios::trunc | If the file opened for output operations already existed before, its previous content is deleted and replaced by the new one. |
All these flags can be combined using the bitwise operator OR (|). For example, if we want to open the file example.bin in binary mode to add data we could do it by the following call to member function open():
ofstream myfile;
myfile.open ("example.bin", ios::out | ios::app | ios::binary);
Each one of the open() member functions of the classes ofstream, ifstream and fstream has a default mode that is used if the file is opened without a second argument:
| Class | default mode parameter |
| ofstream | ios::out |
| ifstream | ios::in |
| fstream | ios::in | ios::out |
For ifstream and ofstream classes, ios::in and ios::out are automatically and respectively assumed, even if a mode that does not include them is passed as second argument to the open() member function.
The default value is only applied if the function is called without specifying any value for the mode parameter. If the function is called with any value in that parameter the default mode is overridden, not combined.
File streams opened in binary mode perform input and output operations independently of any format considerations. Non-binary files are known as text files, and some translations may occur due to formatting of some special characters (like newline and carriage return characters).
Since the first task that is performed on a file stream object is generally to open a file, these three classes include a constructor that automatically calls the open() member function and has the exact same parameters as this member. Therefore, we could also have declared the previous myfile object and conducted the same opening operation in our previous example by writing:
ofstream myfile ("example.bin", ios::out | ios::app | ios::binary);
Combining object construction and stream opening in a single statement. Both forms to open a file are valid and equivalent.
To check if a file stream was successful opening a file, you can do it by calling to member is_open() with no arguments. This member function returns a bool value of true in the case that indeed the stream object is associated with an open file, or false otherwise:
if (myfile.is_open()) { /* ok, proceed with output */ }
Closing a file
When we are finished with our input and output operations on a file we shall close it so that its resources become available again. In order to do that we have to call the stream's member function close(). This member function takes no parameters, and what it does is to flush the associated buffers and close the file:
myfile.close();
Once this member function is called, the stream object can be used to open another file, and the file is available again to be opened by other processes.
In case that an object is destructed while still associated with an open file, the destructor automatically calls the member function close().
Text files
Text file streams are those where we do not include the ios::binary flag in their opening mode. These files are designed to store text and thus all values that we input or output from/to them can suffer some formatting transformations, which do not necessarily correspond to their literal binary value.
Data output operations on text files are performed in the same way we operated with cout:
// writing on a text file
#include
#include
using namespace std;
int main () {
ofstream myfile ("example.txt");
if (myfile.is_open())
{
myfile << "This is a line.\n";
myfile << "This is another line.\n";
myfile.close();
}
else cout << "Unable to open file";
return 0;
}
[file example.txt]
This is a line.
This is another line.
Data input from a file can also be performed in the same way that we did with cin:
// reading a text file
#include
#include
#include
using namespace std;
int main () {
string line;
ifstream myfile ("example.txt");
if (myfile.is_open())
{
while (! myfile.eof() )
{
getline (myfile,line);
cout << line << endl;
}
myfile.close();
}
else cout << "Unable to open file";
return 0;
}
This is a line.
This is another line.
This last example reads a text file and prints out its content on the screen. Notice how we have used a new member function, called eof() that returns true in the case that the end of the file has been reached. We have created a while loop that finishes when indeed myfile.eof() becomes true (i.e., the end of the file has been reached).
Checking state flags
In addition to eof(), which checks if the end of file has been reached, other member functions exist to check the state of a stream (all of them return a bool value):
bad()
Returns true if a reading or writing operation fails. For example in the case that we try to write to a file that is not open for writing or if the device where we try to write has no space left.
fail()
Returns true in the same cases as bad(), but also in the case that a format error happens, like when an alphabetical character is extracted when we are trying to read an integer number.
eof()
Returns true if a file open for reading has reached the end.
good()
It is the most generic state flag: it returns false in the same cases in which calling any of the previous functions would return true.
In order to reset the state flags checked by any of these member functions we have just seen we can use the member function clear(), which takes no parameters.
get and put stream pointers
All i/o streams objects have, at least, one internal stream pointer:
ifstream, like istream, has a pointer known as the get pointer that points to the element to be read in the next input operation.
ofstream, like ostream, has a pointer known as the put pointer that points to the location where the next element has to be written.
Finally, fstream, inherits both, the get and the put pointers, from iostream (which is itself derived from both istream and ostream).
These internal stream pointers that point to the reading or writing locations within a stream can be manipulated using the following member functions:
tellg() and tellp()
These two member functions have no parameters and return a value of the member type pos_type, which is an integer data type representing the current position of the get stream pointer (in the case of tellg) or the put stream pointer (in the case of tellp).
seekg() and seekp()
These functions allow us to change the position of the get and put stream pointers. Both functions are overloaded with two different prototypes. The first prototype is:
seekg ( position );
seekp ( position );
Using this prototype the stream pointer is changed to the absolute position position (counting from the beginning of the file). The type for this parameter is the same as the one returned by functions tellg and tellp: the member type pos_type, which is an integer value.
The other prototype for these functions is:
seekg ( offset, direction );
seekp ( offset, direction );
Using this prototype, the position of the get or put pointer is set to an offset value relative to some specific point determined by the parameter direction. offset is of the member type off_type, which is also an integer type. And direction is of type seekdir, which is an enumerated type (enum) that determines the point from where offset is counted from, and that can take any of the following values:
| ios::beg | offset counted from the beginning of the stream |
| ios::cur | offset counted from the current position of the stream pointer |
| ios::end | offset counted from the end of the stream |
The following example uses the member functions we have just seen to obtain the size of a file:
// obtaining file size
#include
#include
using namespace std;
int main () {
long begin,end;
ifstream myfile ("example.txt");
begin = myfile.tellg();
myfile.seekg (0, ios::end);
end = myfile.tellg();
myfile.close();
cout << "size is: " << (end-begin) << " bytes.\n";
return 0;
}
size is: 40 bytes.
Binary files
In binary files, to input and output data with the extraction and insertion operators (<< and >>) and functions like getline is not efficient, since we do not need to format any data, and data may not use the separation codes used by text files to separate elements (like space, newline, etc...).
File streams include two member functions specifically designed to input and output binary data sequentially: write and read. The first one (write) is a member function of ostream inherited by ofstream. And read is a member function of istream that is inherited by ifstream. Objects of class fstream have both members. Their prototypes are:
write ( memory_block, size );
read ( memory_block, size );
Where memory_block is of type "pointer to char" (char*), and represents the address of an array of bytes where the read data elements are stored or from where the data elements to be written are taken. The size parameter is an integer value that specifies the number of characters to be read or written from/to the memory block.
// reading a complete binary file
#include
#include
using namespace std;
ifstream::pos_type size;
char * memblock;
int main () {
ifstream file ("example.bin", ios::in|ios::binary|ios::ate);
if (file.is_open())
{
size = file.tellg();
memblock = new char [size];
file.seekg (0, ios::beg);
file.read (memblock, size);
file.close();
cout << "the complete file content is in memory";
delete[] memblock;
}
else cout << "Unable to open file";
return 0;
}
the complete file content is in memory
In this example the entire file is read and stored in a memory block. Let's examine how this is done:
First, the file is open with the ios::ate flag, which means that the get pointer will be positioned at the end of the file. This way, when we call to member tellg(), we will directly obtain the size of the file. Notice the type we have used to declare variable size:
ifstream::pos_type size;
ifstream::pos_type is a specific type used for buffer and file positioning and is the type returned by file.tellg(). This type is defined as an integer type, therefore we can conduct on it the same operations we conduct on any other integer value, and can safely be converted to another integer type large enough to contain the size of the file. For a file with a size under 2GB we could use int:
int size;
size = (int) file.tellg();
Once we have obtained the size of the file, we request the allocation of a memory block large enough to hold the entire file:
memblock = new char[size];
Right after that, we proceed to set the get pointer at the beginning of the file (remember that we opened the file with this pointer at the end), then read the entire file, and finally close it:
file.seekg (0, ios::beg);
file.read (memblock, size);
file.close();
At this point we could operate with the data obtained from the file. Our program simply announces that the content of the file is in memory and then terminates.
Buffers and Synchronization
When we operate with file streams, these are associated to an internal buffer of type streambuf. This buffer is a memory block that acts as an intermediary between the stream and the physical file. For example, with an ofstream, each time the member function put (which writes a single character) is called, the character is not written directly to the physical file with which the stream is associated. Instead of that, the character is inserted in that stream's intermediate buffer.
When the buffer is flushed, all the data contained in it is written to the physical medium (if it is an output stream) or simply freed (if it is an input stream). This process is called synchronization and takes place under any of the following circumstances:
* When the file is closed: before closing a file all buffers that have not yet been flushed are synchronized and all pending data is written or read to the physical medium.
* When the buffer is full: Buffers have a certain size. When the buffer is full it is automatically synchronized.
* Explicitly, with manipulators: When certain manipulators are used on streams, an explicit synchronization takes place. These manipulators are: flush and endl.
* Explicitly, with member function sync(): Calling stream's member function sync(), which takes no parameters, causes an immediate synchronization. This function returns an int value equal to -1 if the stream has no associated buffer or in case of failure. Otherwise (if the stream buffer was successfully synchronized) it returns 0.
Preprocessor directives
Preprocessor directives
Preprocessor directives are lines included in the code of our programs that are not program statements but directives for the preprocessor. These lines are always preceded by a hash sign (#). The preprocessor is executed before the actual compilation of code begins, therefore the preprocessor digests all these directives before any code is generated by the statements.
These preprocessor directives extend only across a single line of code. As soon as a newline character is found, the preprocessor directive is considered to end. No semicolon (;) is expected at the end of a preprocessor directive. The only way a preprocessor directive can extend through more than one line is by preceding the newline character at the end of the line by a backslash (\).
macro definitions (#define, #undef)
To define preprocessor macros we can use #define. Its format is:
#define identifier replacement
When the preprocessor encounters this directive, it replaces any occurrence of identifier in the rest of the code by replacement. This replacement can be an expression, a statement, a block or simply anything. The preprocessor does not understand C++, it simply replaces any occurrence of identifier by replacement.
#define TABLE_SIZE 100
int table1[TABLE_SIZE];
int table2[TABLE_SIZE];
After the preprocessor has replaced TABLE_SIZE, the code becomes equivalent to:
int table1[100];
int table2[100];
This use of #define as constant definer is already known by us from previous tutorials, but #define can work also with parameters to define function macros:
#define getmax(a,b) a>b?a:b
This would replace any occurrence of getmax followed by two arguments by the replacement expression, but also replacing each argument by its identifier, exactly as you would expect if it was a function:
// function macro
#include
using namespace std;
#define getmax(a,b) ((a)>(b)?(a):(b))
int main()
{
int x=5, y;
y= getmax(x,2);
cout << y << endl;
cout << getmax(7,x) << endl;
return 0;
}
5
7
Defined macros are not affected by block structure. A macro lasts until it is undefined with the #undef preprocessor directive:
#define TABLE_SIZE 100
int table1[TABLE_SIZE];
#undef TABLE_SIZE
#define TABLE_SIZE 200
int table2[TABLE_SIZE];
This would generate the same code as:
int table1[100];
int table2[200];
Function macro definitions accept two special operators (# and ##) in the replacement sequence:
If the operator # is used before a parameter is used in the replacement sequence, that parameter is replaced by a string literal (as if it were enclosed between double quotes)
#define str(x) #x
cout << str(test);
This would be translated into:
cout << "test";
The operator ## concatenates two arguments leaving no blank spaces between them:
#define glue(a,b) a ## b
glue(c,out) << "test";
This would also be translated into:
cout << "test";
Because preprocessor replacements happen before any C++ syntax check, macro definitions can be a tricky feature, but be careful: code that relies heavily on complicated macros may result obscure to other programmers, since the syntax they expect is on many occasions different from the regular expressions programmers expect in C++.
Conditional inclusions (#ifdef, #ifndef, #if, #endif, #else and #elif)
These directives allow to include or discard part of the code of a program if a certain condition is met.
#ifdef allows a section of a program to be compiled only if the macro that is specified as the parameter has been defined, no matter which its value is. For example:
#ifdef TABLE_SIZE
int table[TABLE_SIZE];
#endif
In this case, the line of code int table[TABLE_SIZE]; is only compiled if TABLE_SIZE was previously defined with #define, independently of its value. If it was not defined, that line will not be included in the program compilation.
#ifndef serves for the exact opposite: the code between #ifndef and #endif directives is only compiled if the specified identifier has not been previously defined. For example:
#ifndef TABLE_SIZE
#define TABLE_SIZE 100
#endif
int table[TABLE_SIZE];
In this case, if when arriving at this piece of code, the TABLE_SIZE macro has not been defined yet, it would be defined to a value of 100. If it already existed it would keep its previous value since the #define directive would not be executed.
The #if, #else and #elif (i.e., "else if") directives serve to specify some condition to be met in order for the portion of code they surround to be compiled. The condition that follows #if or #elif can only evaluate constant expressions, including macro expressions. For example:
#if TABLE_SIZE>200
#undef TABLE_SIZE
#define TABLE_SIZE 200
#elif TABLE_SIZE<50
#undef TABLE_SIZE
#define TABLE_SIZE 50
#else
#undef TABLE_SIZE
#define TABLE_SIZE 100
#endif
int table[TABLE_SIZE];
Notice how the whole structure of #if, #elif and #else chained directives ends with #endif.
The behavior of #ifdef and #ifndef can also be achieved by using the special operators defined and !defined respectively in any #if or #elif directive:
#if !defined TABLE_SIZE
#define TABLE_SIZE 100
#elif defined ARRAY_SIZE
#define TABLE_SIZE ARRAY_SIZE
int table[TABLE_SIZE];
Line control (#line)
When we compile a program and some error happen during the compiling process, the compiler shows an error message with references to the name of the file where the error happened and a line number, so it is easier to find the code generating the error.
The #line directive allows us to control both things, the line numbers within the code files as well as the file name that we want that appears when an error takes place. Its format is:
#line number "filename"
Where number is the new line number that will be assigned to the next code line. The line numbers of successive lines will be increased one by one from this point on.
"filename" is an optional parameter that allows to redefine the file name that will be shown. For example:
#line 20 "assigning variable"
int a?;
This code will generate an error that will be shown as error in file "assigning variable", line 20.
Error directive (#error)
This directive aborts the compilation process when it is found, generating a compilation the error that can be specified as its parameter:
#ifndef __cplusplus
#error A C++ compiler is required!
#endif
This example aborts the compilation process if the macro name __cplusplus is not defined (this macro name is defined by default in all C++ compilers).
Source file inclusion (#include)
This directive has also been used assiduously in other sections of this tutorial. When the preprocessor finds an #include directive it replaces it by the entire content of the specified file. There are two ways to specify a file to be included:
#include "file"
#include
The only difference between both expressions is the places (directories) where the compiler is going to look for the file. In the first case where the file name is specified between double-quotes, the file is searched first in the same directory that includes the file containing the directive. In case that it is not there, the compiler searches the file in the default directories where it is configured to look for the standard header files.
If the file name is enclosed between angle-brackets <> the file is searched directly where the compiler is configured to look for the standard header files. Therefore, standard header files are usually included in angle-brackets, while other specific header files are included using quotes.
Pragma directive (#pragma)
This directive is used to specify diverse options to the compiler. These options are specific for the platform and the compiler you use. Consult the manual or the reference of your compiler for more information on the possible parameters that you can define with #pragma.
If the compiler does not support a specific argument for #pragma, it is ignored - no error is generated.
Predefined macro names
The following macro names are defined at any time:
For example:
// standard macro names
#include
using namespace std;
int main()
{
cout << "This is the line number " << __LINE__;
cout << " of file " << __FILE__ << ".\n";
cout << "Its compilation began " << __DATE__;
cout << " at " << __TIME__ << ".\n";
cout << "The compiler gives a __cplusplus value of " << __cplusplus;
return 0;
}
This is the line number 7 of file /home/jay/stdmacronames.cpp.
Its compilation began Nov 1 2005 at 10:12:29.
The compiler gives a __cplusplus value of 1
Preprocessor directives are lines included in the code of our programs that are not program statements but directives for the preprocessor. These lines are always preceded by a hash sign (#). The preprocessor is executed before the actual compilation of code begins, therefore the preprocessor digests all these directives before any code is generated by the statements.
These preprocessor directives extend only across a single line of code. As soon as a newline character is found, the preprocessor directive is considered to end. No semicolon (;) is expected at the end of a preprocessor directive. The only way a preprocessor directive can extend through more than one line is by preceding the newline character at the end of the line by a backslash (\).
macro definitions (#define, #undef)
To define preprocessor macros we can use #define. Its format is:
#define identifier replacement
When the preprocessor encounters this directive, it replaces any occurrence of identifier in the rest of the code by replacement. This replacement can be an expression, a statement, a block or simply anything. The preprocessor does not understand C++, it simply replaces any occurrence of identifier by replacement.
#define TABLE_SIZE 100
int table1[TABLE_SIZE];
int table2[TABLE_SIZE];
After the preprocessor has replaced TABLE_SIZE, the code becomes equivalent to:
int table1[100];
int table2[100];
This use of #define as constant definer is already known by us from previous tutorials, but #define can work also with parameters to define function macros:
#define getmax(a,b) a>b?a:b
This would replace any occurrence of getmax followed by two arguments by the replacement expression, but also replacing each argument by its identifier, exactly as you would expect if it was a function:
// function macro
#include
using namespace std;
#define getmax(a,b) ((a)>(b)?(a):(b))
int main()
{
int x=5, y;
y= getmax(x,2);
cout << y << endl;
cout << getmax(7,x) << endl;
return 0;
}
5
7
Defined macros are not affected by block structure. A macro lasts until it is undefined with the #undef preprocessor directive:
#define TABLE_SIZE 100
int table1[TABLE_SIZE];
#undef TABLE_SIZE
#define TABLE_SIZE 200
int table2[TABLE_SIZE];
This would generate the same code as:
int table1[100];
int table2[200];
Function macro definitions accept two special operators (# and ##) in the replacement sequence:
If the operator # is used before a parameter is used in the replacement sequence, that parameter is replaced by a string literal (as if it were enclosed between double quotes)
#define str(x) #x
cout << str(test);
This would be translated into:
cout << "test";
The operator ## concatenates two arguments leaving no blank spaces between them:
#define glue(a,b) a ## b
glue(c,out) << "test";
This would also be translated into:
cout << "test";
Because preprocessor replacements happen before any C++ syntax check, macro definitions can be a tricky feature, but be careful: code that relies heavily on complicated macros may result obscure to other programmers, since the syntax they expect is on many occasions different from the regular expressions programmers expect in C++.
Conditional inclusions (#ifdef, #ifndef, #if, #endif, #else and #elif)
These directives allow to include or discard part of the code of a program if a certain condition is met.
#ifdef allows a section of a program to be compiled only if the macro that is specified as the parameter has been defined, no matter which its value is. For example:
#ifdef TABLE_SIZE
int table[TABLE_SIZE];
#endif
In this case, the line of code int table[TABLE_SIZE]; is only compiled if TABLE_SIZE was previously defined with #define, independently of its value. If it was not defined, that line will not be included in the program compilation.
#ifndef serves for the exact opposite: the code between #ifndef and #endif directives is only compiled if the specified identifier has not been previously defined. For example:
#ifndef TABLE_SIZE
#define TABLE_SIZE 100
#endif
int table[TABLE_SIZE];
In this case, if when arriving at this piece of code, the TABLE_SIZE macro has not been defined yet, it would be defined to a value of 100. If it already existed it would keep its previous value since the #define directive would not be executed.
The #if, #else and #elif (i.e., "else if") directives serve to specify some condition to be met in order for the portion of code they surround to be compiled. The condition that follows #if or #elif can only evaluate constant expressions, including macro expressions. For example:
#if TABLE_SIZE>200
#undef TABLE_SIZE
#define TABLE_SIZE 200
#elif TABLE_SIZE<50
#undef TABLE_SIZE
#define TABLE_SIZE 50
#else
#undef TABLE_SIZE
#define TABLE_SIZE 100
#endif
int table[TABLE_SIZE];
Notice how the whole structure of #if, #elif and #else chained directives ends with #endif.
The behavior of #ifdef and #ifndef can also be achieved by using the special operators defined and !defined respectively in any #if or #elif directive:
#if !defined TABLE_SIZE
#define TABLE_SIZE 100
#elif defined ARRAY_SIZE
#define TABLE_SIZE ARRAY_SIZE
int table[TABLE_SIZE];
Line control (#line)
When we compile a program and some error happen during the compiling process, the compiler shows an error message with references to the name of the file where the error happened and a line number, so it is easier to find the code generating the error.
The #line directive allows us to control both things, the line numbers within the code files as well as the file name that we want that appears when an error takes place. Its format is:
#line number "filename"
Where number is the new line number that will be assigned to the next code line. The line numbers of successive lines will be increased one by one from this point on.
"filename" is an optional parameter that allows to redefine the file name that will be shown. For example:
#line 20 "assigning variable"
int a?;
This code will generate an error that will be shown as error in file "assigning variable", line 20.
Error directive (#error)
This directive aborts the compilation process when it is found, generating a compilation the error that can be specified as its parameter:
#ifndef __cplusplus
#error A C++ compiler is required!
#endif
This example aborts the compilation process if the macro name __cplusplus is not defined (this macro name is defined by default in all C++ compilers).
Source file inclusion (#include)
This directive has also been used assiduously in other sections of this tutorial. When the preprocessor finds an #include directive it replaces it by the entire content of the specified file. There are two ways to specify a file to be included:
#include "file"
#include
The only difference between both expressions is the places (directories) where the compiler is going to look for the file. In the first case where the file name is specified between double-quotes, the file is searched first in the same directory that includes the file containing the directive. In case that it is not there, the compiler searches the file in the default directories where it is configured to look for the standard header files.
If the file name is enclosed between angle-brackets <> the file is searched directly where the compiler is configured to look for the standard header files. Therefore, standard header files are usually included in angle-brackets, while other specific header files are included using quotes.
Pragma directive (#pragma)
This directive is used to specify diverse options to the compiler. These options are specific for the platform and the compiler you use. Consult the manual or the reference of your compiler for more information on the possible parameters that you can define with #pragma.
If the compiler does not support a specific argument for #pragma, it is ignored - no error is generated.
Predefined macro names
The following macro names are defined at any time:
| Macro | Value |
| __LINE__ | Integer value representing the current line in the source code file being compiled. |
| __FILE__ | A string literal containing the presumed name of the source file being compiled. |
| _DATE__ | A string literal in the form "Mmm dd yyyy" containing the date in which the compilation process began. |
| _TIME__ | A string literal in the form "hh:mm:ss" containing the time at which the compilation process began. |
| __cplusplus | An integer value. All C++ compilers have this constant defined to some value. If the compiler is fully compliant with the C++ standard its value is equal or greater than 199711L depending on the version of the standard they comply. |
For example:
// standard macro names
#include
using namespace std;
int main()
{
cout << "This is the line number " << __LINE__;
cout << " of file " << __FILE__ << ".\n";
cout << "Its compilation began " << __DATE__;
cout << " at " << __TIME__ << ".\n";
cout << "The compiler gives a __cplusplus value of " << __cplusplus;
return 0;
}
This is the line number 7 of file /home/jay/stdmacronames.cpp.
Its compilation began Nov 1 2005 at 10:12:29.
The compiler gives a __cplusplus value of 1
Type Casting
Type Casting
Converting an expression of a given type into another type is known as type-casting. We have already seen some ways to type cast:
Implicit conversion
Implicit conversions do not require any operator. They are automatically performed when a value is copied to a compatible type. For example:
short a=2000;
int b;
b=a;
Here, the value of a has been promoted from short to int and we have not had to specify any type-casting operator. This is known as a standard conversion. Standard conversions affect fundamental data types, and allow conversions such as the conversions between numerical types (short to int, int to float, double to int...), to or from bool, and some pointer conversions. Some of these conversions may imply a loss of precision, which the compiler can signal with a warning. This can be avoided with an explicit conversion.
Implicit conversions also include constructor or operator conversions, which affect classes that include specific constructors or operator functions to perform conversions. For example:
class A {};
class B { public: B (A a) {} };
A a;
B b=a;
Here, a implicit conversion happened between objects of class A and class B, because B has a constructor that takes an object of class A as parameter. Therefore implicit conversions from A to B are allowed.
Explicit conversion
C++ is a strong-typed language. Many conversions, specially those that imply a different interpretation of the value, require an explicit conversion. We have already seen two notations for explicit type conversion: functional and c-like casting:
short a=2000;
int b;
b = (int) a; // c-like cast notation
b = int (a); // functional notation
The functionality of these explicit conversion operators is enough for most needs with fundamental data types. However, these operators can be applied indiscriminately on classes and pointers to classes, which can lead to code that while being syntactically correct can cause runtime errors. For example, the following code is syntactically correct:
// class type-casting
#include
using namespace std;
class CDummy {
float i,j;
};
class CAddition {
int x,y;
public:
CAddition (int a, int b) { x=a; y=b; }
int result() { return x+y;}
};
int main () {
CDummy d;
CAddition * padd;
padd = (CAddition*) &d;
cout << padd->result();
return 0;
}
The program declares a pointer to CAddition, but then it assigns to it a reference to an object of another incompatible type using explicit type-casting:
padd = (CAddition*) &d;
Traditional explicit type-casting allows to convert any pointer into any other pointer type, independently of the types they point to. The subsequent call to member result will produce either a run-time error or a unexpected result.
In order to control these types of conversions between classes, we have four specific casting operators: dynamic_cast, reinterpret_cast, static_cast and const_cast. Their format is to follow the new type enclosed between angle-brackets (<>) and immediately after, the expression to be converted between parentheses.
dynamic_cast (expression)
reinterpret_cast (expression)
static_cast (expression)
const_cast (expression)
The traditional type-casting equivalents to these expressions would be:
(new_type) expression
new_type (expression)
but each one with its own special characteristics:
dynamic_cast
dynamic_cast can be used only with pointers and references to objects. Its purpose is to ensure that the result of the type conversion is a valid complete object of the requested class.
Therefore, dynamic_cast is always successful when we cast a class to one of its base classes:
class CBase { };
class CDerived: public CBase { };
CBase b; CBase* pb;
CDerived d; CDerived* pd;
pb = dynamic_cast(&d); // ok: derived-to-base
pd = dynamic_cast(&b); // wrong: base-to-derived
The second conversion in this piece of code would produce a compilation error since base-to-derived conversions are not allowed with dynamic_cast unless the base class is polymorphic.
When a class is polymorphic, dynamic_cast performs a special checking during runtime to ensure that the expression yields a valid complete object of the requested class:
// dynamic_cast
#include
#include
using namespace std;
class CBase { virtual void dummy() {} };
class CDerived: public CBase { int a; };
int main () {
try {
CBase * pba = new CDerived;
CBase * pbb = new CBase;
CDerived * pd;
pd = dynamic_cast(pba);
if (pd==0) cout << "Null pointer on first type-cast" << endl;
pd = dynamic_cast(pbb);
if (pd==0) cout << "Null pointer on second type-cast" << endl;
} catch (exception& e) {cout << "Exception: " << e.what();}
return 0;
}
Null pointer on second type-cast
Compatibility note: dynamic_cast requires the Run-Time Type Information (RTTI) to keep track of dynamic types. Some compilers support this feature as an option which is disabled by default. This must be enabled for runtime type checking using dynamic_cast to work properly.
The code tries to perform two dynamic casts from pointer objects of type CBase* (pba and pbb) to a pointer object of type CDerived*, but only the first one is successful. Notice their respective initializations:
CBase * pba = new CDerived;
CBase * pbb = new CBase;
Even though both are pointers of type CBase*, pba points to an object of type CDerived, while pbb points to an object of type CBase. Thus, when their respective type-castings are performed using dynamic_cast, pba is pointing to a full object of class CDerived, whereas pbb is pointing to an object of class CBase, which is an incomplete object of class CDerived.
When dynamic_cast cannot cast a pointer because it is not a complete object of the required class -as in the second conversion in the previous example- it returns a null pointer to indicate the failure. If dynamic_cast is used to convert to a reference type and the conversion is not possible, an exception of type bad_cast is thrown instead.
dynamic_cast can also cast null pointers even between pointers to unrelated classes, and can also cast pointers of any type to void pointers (void*).
static_cast
static_cast can perform conversions between pointers to related classes, not only from the derived class to its base, but also from a base class to its derived. This ensures that at least the classes are compatible if the proper object is converted, but no safety check is performed during runtime to check if the object being converted is in fact a full object of the destination type. Therefore, it is up to the programmer to ensure that the conversion is safe. On the other side, the overhead of the type-safety checks of dynamic_cast is avoided.
class CBase {};
class CDerived: public CBase {};
CBase * a = new CBase;
CDerived * b = static_cast(a);
This would be valid, although b would point to an incomplete object of the class and could lead to runtime errors if dereferenced.
static_cast can also be used to perform any other non-pointer conversion that could also be performed implicitly, like for example standard conversion between fundamental types:
double d=3.14159265;
int i = static_cast(d);
Or any conversion between classes with explicit constructors or operator functions as described in "implicit conversions" above.
reinterpret_cast
reinterpret_cast converts any pointer type to any other pointer type, even of unrelated classes. The operation result is a simple binary copy of the value from one pointer to the other. All pointer conversions are allowed: neither the content pointed nor the pointer type itself is checked.
It can also cast pointers to or from integer types. The format in which this integer value represents a pointer is platform-specific. The only guarantee is that a pointer cast to an integer type large enough to fully contain it, is granted to be able to be cast back to a valid pointer.
The conversions that can be performed by reinterpret_cast but not by static_cast have no specific uses in C++ are low-level operations, whose interpretation results in code which is generally system-specific, and thus non-portable. For example:
class A {};
class B {};
A * a = new A;
B * b = reinterpret_cast(a);
This is valid C++ code, although it does not make much sense, since now we have a pointer that points to an object of an incompatible class, and thus dereferencing it is unsafe.
const_cast
This type of casting manipulates the constness of an object, either to be set or to be removed. For example, in order to pass a const argument to a function that expects a non-constant parameter:
// const_cast
#include
using namespace std;
void print (char * str)
{
cout << str << endl;
}
int main () {
const char * c = "sample text";
print ( const_cast (c) );
return 0;
}
sample text
typeid
typeid allows to check the type of an expression:
typeid (expression)
This operator returns a reference to a constant object of type type_info that is defined in the standard header file. This returned value can be compared with another one using operators == and != or can serve to obtain a null-terminated character sequence representing the data type or class name by using its name() member.
// typeid
#include
#include
using namespace std;
int main () {
int * a,b;
a=0; b=0;
if (typeid(a) != typeid(b))
{
cout << "a and b are of different types:\n";
cout << "a is: " << typeid(a).name() << '\n';
cout << "b is: " << typeid(b).name() << '\n';
}
return 0;
}
a and b are of different types:
a is: int *
b is: int
When typeid is applied to classes typeid uses the RTTI to keep track of the type of dynamic objects. When typeid is applied to an expression whose type is a polymorphic class, the result is the type of the most derived complete object:
// typeid, polymorphic class
#include
#include
#include
using namespace std;
class CBase { virtual void f(){} };
class CDerived : public CBase {};
int main () {
try {
CBase* a = new CBase;
CBase* b = new CDerived;
cout << "a is: " << typeid(a).name() << '\n';
cout << "b is: " << typeid(b).name() << '\n';
cout << "*a is: " << typeid(*a).name() << '\n';
cout << "*b is: " << typeid(*b).name() << '\n';
} catch (exception& e) { cout << "Exception: " << e.what() << endl; }
return 0;
}
a is: class CBase *
b is: class CBase *
*a is: class CBase
*b is: class CDerived
Notice how the type that typeid considers for pointers is the pointer type itself (both a and b are of type class CBase *). However, when typeid is applied to objects (like *a and *b) typeid yields their dynamic type (i.e. the type of their most derived complete object).
If the type typeid evaluates is a pointer preceded by the dereference operator (*), and this pointer has a null value, typeid throws a bad_typeid exception.
Converting an expression of a given type into another type is known as type-casting. We have already seen some ways to type cast:
Implicit conversion
Implicit conversions do not require any operator. They are automatically performed when a value is copied to a compatible type. For example:
short a=2000;
int b;
b=a;
Here, the value of a has been promoted from short to int and we have not had to specify any type-casting operator. This is known as a standard conversion. Standard conversions affect fundamental data types, and allow conversions such as the conversions between numerical types (short to int, int to float, double to int...), to or from bool, and some pointer conversions. Some of these conversions may imply a loss of precision, which the compiler can signal with a warning. This can be avoided with an explicit conversion.
Implicit conversions also include constructor or operator conversions, which affect classes that include specific constructors or operator functions to perform conversions. For example:
class A {};
class B { public: B (A a) {} };
A a;
B b=a;
Here, a implicit conversion happened between objects of class A and class B, because B has a constructor that takes an object of class A as parameter. Therefore implicit conversions from A to B are allowed.
Explicit conversion
C++ is a strong-typed language. Many conversions, specially those that imply a different interpretation of the value, require an explicit conversion. We have already seen two notations for explicit type conversion: functional and c-like casting:
short a=2000;
int b;
b = (int) a; // c-like cast notation
b = int (a); // functional notation
The functionality of these explicit conversion operators is enough for most needs with fundamental data types. However, these operators can be applied indiscriminately on classes and pointers to classes, which can lead to code that while being syntactically correct can cause runtime errors. For example, the following code is syntactically correct:
// class type-casting
#include
using namespace std;
class CDummy {
float i,j;
};
class CAddition {
int x,y;
public:
CAddition (int a, int b) { x=a; y=b; }
int result() { return x+y;}
};
int main () {
CDummy d;
CAddition * padd;
padd = (CAddition*) &d;
cout << padd->result();
return 0;
}
The program declares a pointer to CAddition, but then it assigns to it a reference to an object of another incompatible type using explicit type-casting:
padd = (CAddition*) &d;
Traditional explicit type-casting allows to convert any pointer into any other pointer type, independently of the types they point to. The subsequent call to member result will produce either a run-time error or a unexpected result.
In order to control these types of conversions between classes, we have four specific casting operators: dynamic_cast, reinterpret_cast, static_cast and const_cast. Their format is to follow the new type enclosed between angle-brackets (<>) and immediately after, the expression to be converted between parentheses.
dynamic_cast
reinterpret_cast
static_cast
const_cast
The traditional type-casting equivalents to these expressions would be:
(new_type) expression
new_type (expression)
but each one with its own special characteristics:
dynamic_cast
dynamic_cast can be used only with pointers and references to objects. Its purpose is to ensure that the result of the type conversion is a valid complete object of the requested class.
Therefore, dynamic_cast is always successful when we cast a class to one of its base classes:
class CBase { };
class CDerived: public CBase { };
CBase b; CBase* pb;
CDerived d; CDerived* pd;
pb = dynamic_cast
pd = dynamic_cast
The second conversion in this piece of code would produce a compilation error since base-to-derived conversions are not allowed with dynamic_cast unless the base class is polymorphic.
When a class is polymorphic, dynamic_cast performs a special checking during runtime to ensure that the expression yields a valid complete object of the requested class:
// dynamic_cast
#include
#include
using namespace std;
class CBase { virtual void dummy() {} };
class CDerived: public CBase { int a; };
int main () {
try {
CBase * pba = new CDerived;
CBase * pbb = new CBase;
CDerived * pd;
pd = dynamic_cast
if (pd==0) cout << "Null pointer on first type-cast" << endl;
pd = dynamic_cast
if (pd==0) cout << "Null pointer on second type-cast" << endl;
} catch (exception& e) {cout << "Exception: " << e.what();}
return 0;
}
Null pointer on second type-cast
Compatibility note: dynamic_cast requires the Run-Time Type Information (RTTI) to keep track of dynamic types. Some compilers support this feature as an option which is disabled by default. This must be enabled for runtime type checking using dynamic_cast to work properly.
The code tries to perform two dynamic casts from pointer objects of type CBase* (pba and pbb) to a pointer object of type CDerived*, but only the first one is successful. Notice their respective initializations:
CBase * pba = new CDerived;
CBase * pbb = new CBase;
Even though both are pointers of type CBase*, pba points to an object of type CDerived, while pbb points to an object of type CBase. Thus, when their respective type-castings are performed using dynamic_cast, pba is pointing to a full object of class CDerived, whereas pbb is pointing to an object of class CBase, which is an incomplete object of class CDerived.
When dynamic_cast cannot cast a pointer because it is not a complete object of the required class -as in the second conversion in the previous example- it returns a null pointer to indicate the failure. If dynamic_cast is used to convert to a reference type and the conversion is not possible, an exception of type bad_cast is thrown instead.
dynamic_cast can also cast null pointers even between pointers to unrelated classes, and can also cast pointers of any type to void pointers (void*).
static_cast
static_cast can perform conversions between pointers to related classes, not only from the derived class to its base, but also from a base class to its derived. This ensures that at least the classes are compatible if the proper object is converted, but no safety check is performed during runtime to check if the object being converted is in fact a full object of the destination type. Therefore, it is up to the programmer to ensure that the conversion is safe. On the other side, the overhead of the type-safety checks of dynamic_cast is avoided.
class CBase {};
class CDerived: public CBase {};
CBase * a = new CBase;
CDerived * b = static_cast
This would be valid, although b would point to an incomplete object of the class and could lead to runtime errors if dereferenced.
static_cast can also be used to perform any other non-pointer conversion that could also be performed implicitly, like for example standard conversion between fundamental types:
double d=3.14159265;
int i = static_cast
Or any conversion between classes with explicit constructors or operator functions as described in "implicit conversions" above.
reinterpret_cast
reinterpret_cast converts any pointer type to any other pointer type, even of unrelated classes. The operation result is a simple binary copy of the value from one pointer to the other. All pointer conversions are allowed: neither the content pointed nor the pointer type itself is checked.
It can also cast pointers to or from integer types. The format in which this integer value represents a pointer is platform-specific. The only guarantee is that a pointer cast to an integer type large enough to fully contain it, is granted to be able to be cast back to a valid pointer.
The conversions that can be performed by reinterpret_cast but not by static_cast have no specific uses in C++ are low-level operations, whose interpretation results in code which is generally system-specific, and thus non-portable. For example:
class A {};
class B {};
A * a = new A;
B * b = reinterpret_cast
This is valid C++ code, although it does not make much sense, since now we have a pointer that points to an object of an incompatible class, and thus dereferencing it is unsafe.
const_cast
This type of casting manipulates the constness of an object, either to be set or to be removed. For example, in order to pass a const argument to a function that expects a non-constant parameter:
// const_cast
#include
using namespace std;
void print (char * str)
{
cout << str << endl;
}
int main () {
const char * c = "sample text";
print ( const_cast
return 0;
}
sample text
typeid
typeid allows to check the type of an expression:
typeid (expression)
This operator returns a reference to a constant object of type type_info that is defined in the standard header file
// typeid
#include
#include
using namespace std;
int main () {
int * a,b;
a=0; b=0;
if (typeid(a) != typeid(b))
{
cout << "a and b are of different types:\n";
cout << "a is: " << typeid(a).name() << '\n';
cout << "b is: " << typeid(b).name() << '\n';
}
return 0;
}
a and b are of different types:
a is: int *
b is: int
When typeid is applied to classes typeid uses the RTTI to keep track of the type of dynamic objects. When typeid is applied to an expression whose type is a polymorphic class, the result is the type of the most derived complete object:
// typeid, polymorphic class
#include
#include
#include
using namespace std;
class CBase { virtual void f(){} };
class CDerived : public CBase {};
int main () {
try {
CBase* a = new CBase;
CBase* b = new CDerived;
cout << "a is: " << typeid(a).name() << '\n';
cout << "b is: " << typeid(b).name() << '\n';
cout << "*a is: " << typeid(*a).name() << '\n';
cout << "*b is: " << typeid(*b).name() << '\n';
} catch (exception& e) { cout << "Exception: " << e.what() << endl; }
return 0;
}
a is: class CBase *
b is: class CBase *
*a is: class CBase
*b is: class CDerived
Notice how the type that typeid considers for pointers is the pointer type itself (both a and b are of type class CBase *). However, when typeid is applied to objects (like *a and *b) typeid yields their dynamic type (i.e. the type of their most derived complete object).
If the type typeid evaluates is a pointer preceded by the dereference operator (*), and this pointer has a null value, typeid throws a bad_typeid exception.
Subscribe to:
Posts (Atom)